Vor einigen Jahrzehnten wurden mit Computerprogrammen noch sehr einfache Aufgaben gelöst, wie zum Beispiel das Berechnen von Zinsen aus einem Darlehensvertrag oder die Unterstützung bei der Finanzbuchhaltung in einem Unternehmen. Die Anforderungen an solche Programme waren sehr einfach und haben sich nur sehr selten geändert. Daher war es nicht nötig, die Programme in verschiedene Komponenten mit unterschiedlichen Teilaufgaben zu untergliedern, wie es heute zum Beispiel in der objektorientierten Programmierung üblich ist. Sie bestanden damals nur aus einer einzigen Komponente (siehe folgende Abbildung, links) und werden daher im weiteren Verlauf als Software mit einfacher Struktur bezeichnet.
Eine solche Struktur besitzt allerdings große Nachteile, die mit zunehmender Komplexität der zu lösenden Aufgaben schwer wogen: Die
einzelnen Aufgaben, wie zum Beispiel die Präsentation und Berechnung der Daten, waren nicht klar aufgeteilt. Daher musste die gesamte
Software überarbeitet werden, wenn eine dieser Aufgaben anders gelöst werden sollte. Man stelle sich eine einzige Klasse vor, in der
alle Aufgaben eines Online-Shops gelöst werden. Die Klasse müsste jedes Mal verändert und neu kompiliert werden, wenn die
Benutzerschnittstelle angepasst werden soll, der Bestellprozess sich verändert oder zu einem Artikel zusätziche Informationen
gespeichert werden sollen. Weil die dadurch hervorgerufene Vermischung von Zuständigkeiten zu hohen Wartungskosten führt, ist eine
solche Struktur für komplexe Projekte ungeeignet.
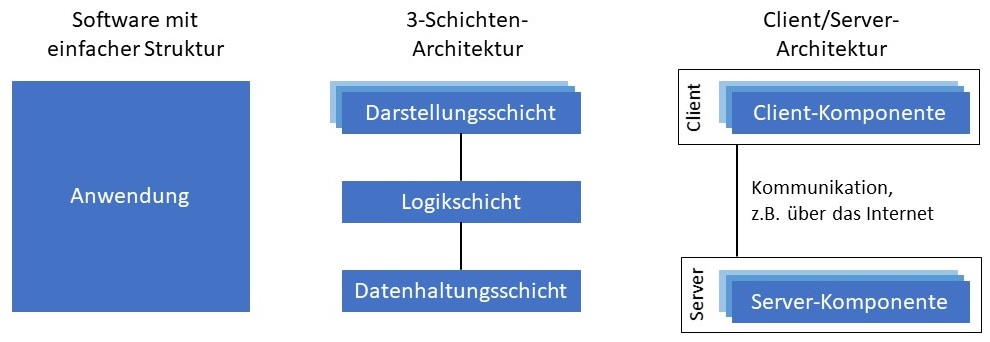
Um die immer komplexer werdenden Anforderungen und die damit verbundenen Wartungskosten beherrschbar zu machen, haben die Softwareentwickler damit begonnen, typische Aufgaben einer Software zu identifizieren und die Software dann nach diesen typischen Aufgaben zu strukturieren. Das Ergebnis waren Softwarearchitekturen wie zum Beispiel die 3-Schichten-Architektur. Eine nach dieser Architektur entwickelte Software besteht aus drei Schichten: der Darstellungsschicht, der Logikschicht und der Datenhaltungsschicht (siehe obige Abbildung, Mitte). Die Aufgaben jeder Schicht sind dabei klar definiert. Die Darstellungsschicht enthält Komponenten zur (visuellen) Repräsentation von Daten und zur Entgegennahme von Benutzereingaben. Sie ist die Schnittstelle zum Anwender der Software. Die für die Anwendungslogik zuständigen Komponenten sind in der Logikschicht zusammengefasst. Sie sind für die korrekte Durchführung der Geschäftsprozesse verantwortlich, wie zum Beispiel der Vorgang zur Bestellung eines Artikels. Zu den Aufgaben der Komponenten in der Datenhaltungsschicht zählen das Erzeugen, Laden, Aktualisieren und Löschen von Datensätzen, die in der Logikschicht verarbeitet und auf der Darstellungsschicht vom Benutzer verwendet wurden. Es sei am Rande darauf hingewiesen, dass die Komponenten einer Schichtenarchitektur im Allgemeinen immer nur mit den Komponenten der benachbarten Schicht Informationen austauschen dürfen. Es ist also zum Beispiel in der 3-Schichten-Architektur nicht erlaubt, dass die Darstellungsschicht unmittelbaren Zugriff auf die Datenhaltungsschicht hat und umgekehrt.
Die klare Trennung der Zuständigkeiten bietet einige Vorteile. Einer der Vorteile ist die Austauschbarkeit der Schichten. So können zum Beispiel dem Anwender je nach Bedarf unterschiedliche Formen der Darstellung präsentiert werden. Wenn ein Kunde den Online-Shop mit seinem Smartphone aufruft, kann die Darstellung reduziert und auf den begrenzten Bildschirm zugeschnitten werden. Verwendet der Kunde hingegen ein Gerät mit größerem Bildschirm, kann eine andere Komponente die Darstellung übernehmen und mehr Details zu den Artikeln anzeigen. Die Komponenten der anderen Schichten bleiben von diesen Veränderungen unberührt.
Doch es gibt auch andere Möglichkeiten, die Architektur einer Software zu strukturieren. Ein weiteres Beispiel ist die Client/Server-Architektur: Sie unterscheidet zwischen Server-Komponenten, die Informationen oder Dienste anbieten, und Client-Komponenten, die Informationen oder Dienste konsumieren (siehe obige Abbildung, rechts). Die Komponenten sind üblicherweise nicht auf dem gleichen Gerät installiert, sondern kommunizieren über ein Netzwerk, beispielsweise über das Internet. Als Beispiel für eine Client/Server-Architektur kann die Internet-Suche genannt werden. Suchmaschinen-Anbieter wie Google, Yahoo oder Microsoft stellen einen Server bereit, der zu einer Liste von Stichwörtern nach einem komplizierten Algorithmus passende Suchergebnisse aus dem Internet liefert. Anwender können diese Dienstleistung konsumieren, indem sie mit einem Client - dem Browser - auf die Suchmaschinen zugreifen.
Der Vorteil solcher Architekturen ist, dass Software über mehrere Geräte verteilt werden kann und Wartungsarbeiten an der Software nur an wenigen zentral verwalteten Server-Komponenten durchgeführt werden müssen. Ein wichtiger Nachteil besteht allerdings in der Verfügbarkeit des Servers: Fällt dieser aus, ist auch die Funktionalität der verbundenen Client-Komponenten beeinträchtigt. Es ist daher aktueller Stand der Technik, Server-Komponenten mithilfe von Virtualisierungs- bzw. Cloud Computing-Technologien ebenfalls auf mehrere Geräte zu verteilen.
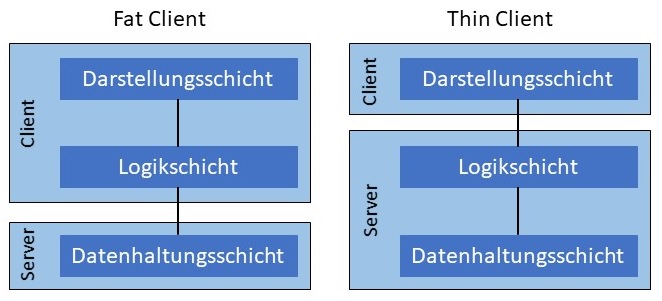
Um beide Vorteile der Client/Server- und der 3-Schichten-Architektur zu nutzen, können die Architekturen kombiniert werden. Hierzu
werden die Schichten auf den Client und den Server aufgeteilt. Je nachdem wie viele Schichten auf dem Client ausgelagert werden, spricht man
von einem Fat Client oder einem Thin Client (siehe folgende Abbildung).
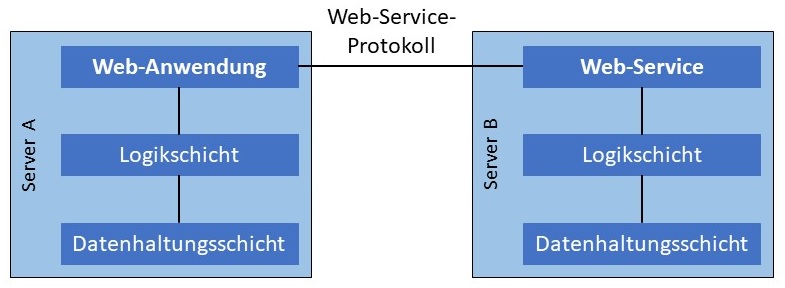
Exkurs
Nicht immer sind die Benutzer eines Systems mit einer verteilten Architektur Menschen, die
Client-Programme bedienen. Häufig kommunizieren Server untereinander, indem sie beispielsweise Rechenergebnisse austauschen. Sogenannte
Web-Services bieten Dienste an, die nicht in erster Linie von Benutzern, sondern von Web-Anwendungen konsumiert werden, die
ihrerseits wieder auf Servern installiert sind. Sie kommunizieren mit den Web-Services über spezielle Web-Service-Protokolle. In solchen
Fällen ist eine Darstellungsschicht nicht notwendig. Die Funktionsweise von Web-Services und die dafür benötigten
Kommunikationsprotokolle werden später behandelt.
Bereits 1979 hat man eine Architektur entwickelt, die der 3-Schichten-Architektur sehr ähnlich ist: die
Model-View-Controller-Architektur (auch MVC-Architektur, siehe nachfolgende Abbildung). Sie ist insbesondere zur Strukturierung von
Web-Anwendungen nützlich.
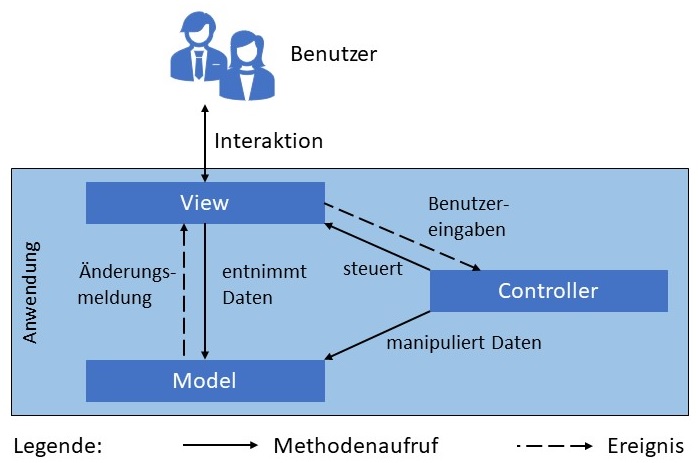
Der Benutzer interagiert mit der Anwendung über die View-Komponenten. Diese entsprechen den Komponenten der Darstellungsschicht und sind somit für die Präsentation der Daten auf der Benutzeroberfläche verantwortlich. Möchte der Benutzer auf Daten zugreifen, können die View-Komponenten diese Informationen direkt von den Komponenten des Modells erfragen. In der 3-Schichten-Architektur ist dies nicht unmittelbar möglich. Das Modell ist dafür verantwortlich, die Daten und fachlichen Funktionen bereitzustellen. Es übernimmt also die Rolle der Datenhaltungsschicht und große Teile der Logikschicht. Wenn sich die Daten im Modell zu einem beliebigen Zeitpunkt ändern, können die Änderungen direkt an die View-Komponente weitergeleitet werden.
Wenn der Benutzer Daten in der Anwendung manipuliert und diese Änderungen bestätigt (z.B. durch Drücken einer Schaltfläche), wird der Controller informiert. Der Controller ist verantwortlich für das Verhalten der Anwendung. In dieser Rolle verarbeitet er die Eingaben, überprüft sie gegebenenfalls und kann dann die View-Komponenten damit beauftragen, dem Benutzer eine Bestätigungs- oder Fehlermeldung anzuzeigen. Auch die Navigation zu einem anderen Fenster bzw. einer anderen Seite gehört zu seinem Aufgabenbereich. Nicht zuletzt ist er dafür verantwortlich, die Benutzereingaben im Modell einzutragen oder Funktionen des Modells aufzurufen.
Ein großer Vorteil der MVC-Architektur besteht darin, dass sie besser zum objektorientierten Design passt als die 3-Schichten-Architektur. Denn Klassen des Fachkonzepts (z.B. Artikel, Kunde etc.) enthalten gleichermaßen Daten - in Form von Attributen - und Funktionen - in Form von Methoden. Es gibt also nach dem objektorientierten Paradigma keine Trennung zwischen Daten und Logik. Außerdem lässt sich somit auch alles Fachliche im Modell zusammenfassen. Auf diese Weise konnten sich umfangreiche Frameworks mit vorgefertigten View- und Controller-Komponenten etablieren, in die Softwareentwickler (fast) nur noch das objektorientierte Klassenmodell einfügen müssen, um eine vollständige Anwendung zu programmieren.
Im weiteren Verlauf wird die MVC-Architektur immer wieder eine wichtige Rolle spielen, zum Beispiel um die Funktionsweise der einzelnen Komponenten einer Web-Anwendung zu erläutern.