Das Paket java.util der Java-Klassenbibliothek bietet allgemein nützliche Datenstrukturen an.
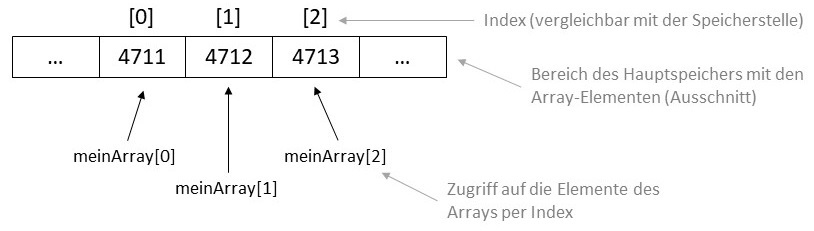
Arrays sind die rudimentärste Art, mehrere gleichartige Objekte in Java zu speichern. Die Elemente eines Arrays
werden sequenziell hintereinander in den Hauptspeicher geschrieben. Man greift auf ein beliebiges Element zu, indem man dessen
Index angibt. Der Index eines Elementes entspricht der Position innerhalb des für den Array reservierten Speicherbereichs.
Zu beachten ist hierbei, dass der Index stets mit 0 beginnt. Der Index auf das letzte Element eines Arrays mit n Elementen ist
dadurch stets [n-1].
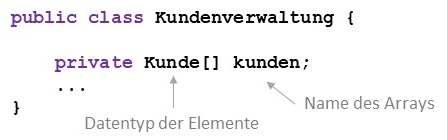
Bei der Deklaration eines Arrays muss der Datentyp festgelegt werden, gefolgt von einer geöffneten und einer geschlossenen
eckigen Klammer und dem Bezeichner.
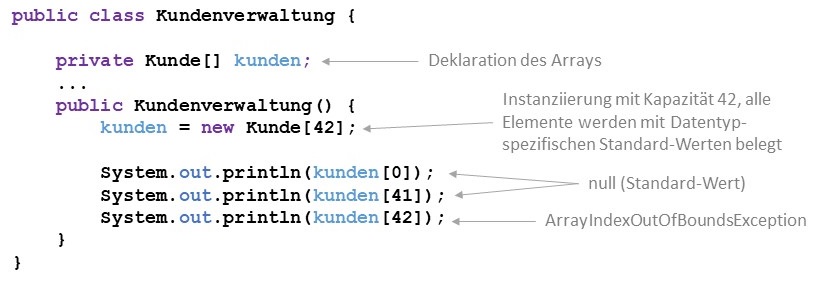
Weil bei der Deklaration noch nicht die Größe des Arrays (im Sinne der maximalen Kapazität) angegeben wird, kann zu
diesem Zeitpunkt auch noch kein Speicherplatz für den Array reserviert werden. Für diesen Zweck ist die Instanziierung
des Arrays vorgesehen. Ähnlich wie bei der Instanziierung herkömmlicher Objekte kommt auch hier das bekannte
Schlüsselwort new zum Einsatz. In den eckigen Klammern ist die gewünschte
Kapazität anzugeben. Bei der Instanziierung ist darauf zu achten, dass die Elemente mit dem Standard-Wert des jeweiligen
Datentyps vorbelegt werden. Das bedeutet, dass zum Beispiel ein int-Array mit lauter Nullen gefüllt wird, ein boolean-Array
mit false-Werten und alle Arrays für komplexe Datentypen (z.B. Strings und eigene Klassen) mit null-Werten.
Falls eine andere Vorbelegung als mit Standardwerten erwünscht ist, kann die Instanziierung auch mit einer Initialisierung
einhergehen. Hierzu gibt man in geschweiften Klammern eine Komma-getrennte Liste von Werteausprägungen an. Durch die
Angabe der Initialwerte wird auch implizit die Kapazität des Arrays festgelegt. Daher fällt die Angabe der Kapazität
in diesem Fall weg. Zu beachten ist ferner, dass die Initialisierung nur zusammen mit der Instanziierung erfolgen kann und nicht
getrennt in einer späteren Anweisung.

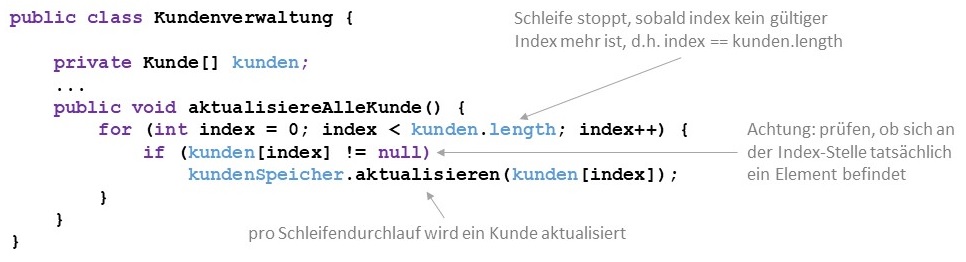
Ist ein Array einmal instanziiert, kann seine Kapazität nicht mehr verändert werden. Um jederzeit einen Überblick
über die Kapazität zu haben, kann auf das Attribut length zugegriffen werden (nicht zu verwechseln mit der Anzahl
der gespeicherten Elemente). Das ist insbesondere dann wichtig, wenn eine separate Methode, in der die Größe des Arrays
üblicherweise unbekannt ist, alle Elemente des Arrays verarbeiten möchte.
| Merke |
In Java ist es möglich, Arrays zu verschachteln. Das heißt, die Elemente eines Arrays sind ebenfalls Arrays. Man
spricht dann von mehrdimensionalen Arrays, da sich die Größe des Arrays bildlich gesehen nicht nur in eine Dimension
ausdehnt, sondern in mindestens zwei. Ein möglicher Anwendungsfall wäre zum Beispiel ein Schachbrett-Array, das
zu jeder Zeile jeweils ein Array mit den dazugehörigen Spielfeldern enthält. Stellt man sich Arrays wie Vektoren
vor, so entspricht ein 2-dimensionales Array einer Matrix. Mehrdimensionale Arrays können deklariert werden, indem man
mehr als ein Paar eckiger Klammern verwendet.
|
Arrays haben einige Vorteile: Ihre Deklaration und Verwendung ist unmittelbarer Bestandteil der Java-Syntax. Es ist also nicht nötig, Bibliotheken für den Einsatz von Arrays zu importieren. Außerdem können Arrays beliebige Typen enthalten, von primitiven Datentypen über Strings bis hin zu selbst programmierten Klassen.
Arrays besitzen aber auch sehr viele Nachteile. Im Gegensatz zu den Collections der Java-Klassenbibliothek muss man sich bei Arrays selbst um die Kapazität kümmern: Ist das Array voll, muss es zur Lafzeit mit einer größeren Kapazität neu initialisiert werden und alle Elemente müssen übertragen werden. Umgekehrt kann es ebenso passieren, dass eine zu hohe Kapazität und folglich unnötigerweise ein viel zu großer Speicherbereich reserviert wurde. Lücken in sortierten Arrays zu schließen ist ebenfalls mit großen Anstrengungen verbunden, weil man für das Aufrücken jedes Folgeelement bewegen muss. Zudem haben Arrays nur eine sehr begrenzte eingebaute Funktionalität: Das heißt, es ist mit einem zusätzlichen Programmieraufwand verbunden, wenn man sie in Form eines Stapels, einer Warteschlange oder einer Menge verwenden möchte. Um diese und viele weitere Lücken zu schließen, wurden die Datenstrukturen der Java-Klassenbibliothek eingeführt.
Die im Paket java.util der Klassenbibliothek definierten Datenstrukturen werden "Collections" genannt. Aufgrund ihrer Bedeutung innerhalb der Programmiersprache wurde um diese Datenstrukturen herum ein ganzes Framework aus Such- und Sortieralgorithmen, Interfaces mit unterschiedlichen Implementierungen und weitere nützliche Klassen gebildet: das "Collections-Framework".
Die Gemeinsamkeiten der Collections werden im gleichlautenden Interface Collection festgehalten. Bis auf Datenstrukturen zur
Realisierung von Mengen wird dieses Interface (oder daraus abgeleitete Interfaces) von allen Klassen des
Collections-Frameworks implementiert. Die Hauptaufgaben bestehen darin, je nach Anwendungsfall Daten effizient zu speichern
und einen genauso effizienten Zugriff darauf zu ermöglichen. Weil beides oft konkurrierende Ziele sind, kann man zwischen
unterschiedlichen Implementierungen wählen, die jeweils entweder die sparsame Speicherung oder den schnellen Zugriff
begünstigen. Die wichtigsten Methoden der Schnittstelle lauten wie folgt:

Beispiele für Datenstrukturen in der Java-Klassenbibliothek java.util:
| Beispiel Programmieraufgabe | Besondere Eigenschaften |
| Artikel im Warenkorb verwalten | Elemente in sequenziell geordneter Reihenfolge. Interface java.util.ListBeispiele für Implementierungen:
|
| Verwaltung des Shop-Sortiments | Keine doppelten Elemente, Reihefolge egal. Interface java.util.SetBeispiele für Implementierungen:
|
| Kundenverwaltung | Schneller Zugriff anhand der Kundennummer. Interface java.util.MapBeispiele für Implementierungen:
|
| "Undo"-Funktion im Bestellprozess | Die Bestellschritte des Benutzers sollen rückgängig gemacht werden können ("Last in, First out"). Interface java.util.DequeBeispiele für Implementierungen:
Interface java.util.ListBeispiele für Implementierungen:
|
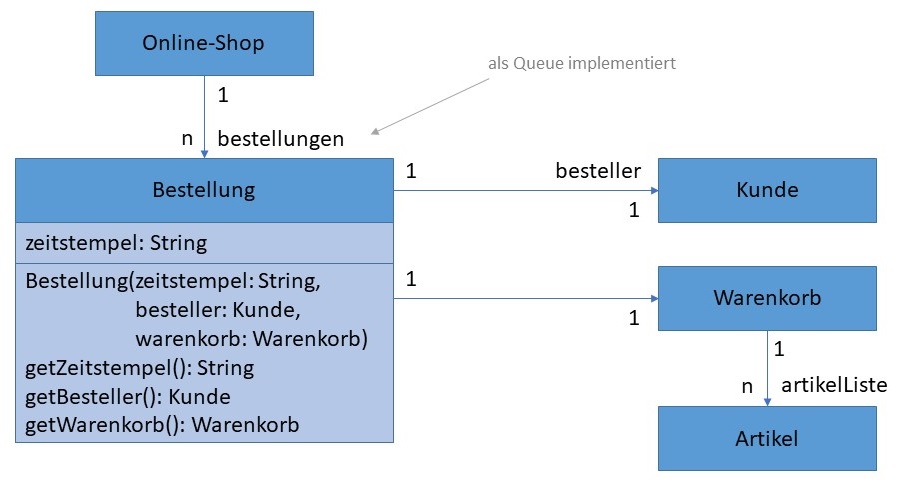
| Warteschlange für Bestellungen | Bearbeitung in der Reihenfolge des Eingangs ("First in, First out"). Interface java.util.QueueBeispiele für Implementierungen:
|
Als erstes Werkzeug, um möglichst einfach und effizient mit Collections arbeiten zu können, soll der Iterator vorgestellt werden. Sein Zweck ist es, über alle Elemente in einer beliebigen Collection zu iterieren - daher auch sein Name. Iterieren bedeutet, alle Elemente, z. B. innerhalb einer Programmschleife, zu durchlaufen und bei Bedarf zu verarbeiten. Der Iterator funktioniert dabei wie ein Lesezeichen, nur handelt es sich hierbei nicht um Seiten eines Buches, sondern um Elemente einer Collection.
Im Collections-Framework ist vorgesehen, dass jede Collection eine eigene Iterator-Implementierung anbietet. Um das sicherzustellen,
wurde das Interface Iterable in der Programmiersprache eingeführt. Es besteht lediglich aus der Methode
iterator() und wird vom Interface Collection erweitert. Auf diese Weise bietet jede Klasse, die das Interface Collection
implementiert, auch einen Iterator an.
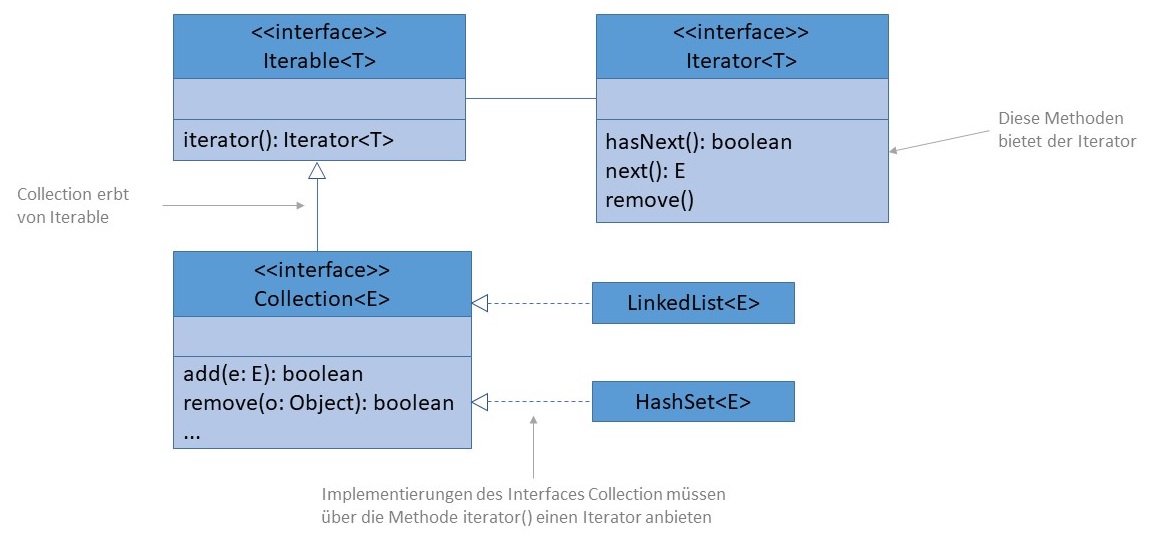
Der Iterator besitzt drei Methoden:
hasNext() kann geprüft werden, ob es an der aktuellen Position des
Iterators noch ein neues Element gibt.next() zurückgegeben werden. Der Iterator
positioniert sich aschließend selbstständig auf das nächste Element.remove() kann das aktuelle Element, auf das sich der Iterator
per next() zuvor positioniert hat, aus der Collection entfernt werden. Das
passiert in diesem Fall schneller, als mit der entsprechenden Methode von Collection, da der Iterator ja bereits auf das zu
löschende Element positioniert ist. Viele Implementierungen von Collection.remove() müssten das Element erst
suchen.Beispiel, wie mithilfe des Iterators fehlerhafte Datensätze bereinigt werden können:

Die Methode erwartet als Parameter eine beliebige Collection, also alle Klassen, die das Interface Collection implementieren. Die
einzige Einschränkung besteht darin, dass die Elemente der Collection Objekte der Klasse "Kunde" oder einer ihrer
Unterklassen sein müssen. Vor der Schleife wird der Iterator der Collection einem eigenen Iterator-Objekt
it zugewiesen.
Ein weiteres nützliches Werkzeug für das Arbeiten mit Collections ist die erweiterte
for-Schleife, sie vereinfacht das Durchlaufen von beliebigen Klassen, die das Interface Iterable implementieren -
also auch alle Collections. Die Syntax ist im Gegensatz zur bereits bekannten for-Schleife leicht abgewandelt: Anstelle von
Initialisierung, Bedingung und Inkrement werden im Kopf der Schleife nur noch zwei Angaben gemacht: die Deklaration eines
Stellvertreters für jedes Collection-Element und die zu verarbeitende Collection selbst. Um die erweiterte for-Schleife auch
syntaktisch von der einfachen Schleife unterscheiden zu können, werden die beiden Argumente nicht mehr mit einem Semikolon,
sondern mit einem Doppelpunkt voneinander getrennt.

Eine Liste speichert eine beliebig große Menge von Daten, deren Elemente eine feste Reihenfolge haben sowie beliebigen
Typs sein können und auf die wahlfrei als auch sequenziell zugegriffen werden kann.
Beispiele für Implementierungen:
java.util.ArrayList (als Array realisiert)java.util.LinkedList (als Verkettung von Referenzdatentypen
realisiert)Neben den Methoden des Collection-Interfaces stellt eine Liste zusätzlich die folgenden Methoden bereit:
void add(int index, E element): Fügt ein Element vom Typ E an der Stelle
index ein und verschiebt bereits vorhandene Elemente um einen Indexwert "nach rechts".boolean addAll(int index, Collection<? extends E> c): Wie oben, fügt
aber eine ganze Collection an der Stelle index ein. Die Elemente der einzufügenden Collection können beliebigen
Typs sein. Voraussetzung ist jedoch, dass er sich zumindest in einer Vererbungsbeziehung mit dem Element-Typ der
Ziel-Collection (E) befindet. Liefert true zurück, falls die Operation erfolgreich war.E remove(int index): Löscht ein Objekt an der Stelle index und gibt eine
Referenz auf das gelöschte Element zurück.set(int index, E element): Tauscht das übergebene Element mit dem
Element an der Position index aus.subList(int fromIndex, int toIndex): Liefert einen Ausschnitt der Liste
zurück (von fromIndex bis exklusive toIndex). Achtung: Da es sich um Referenzdatentypen handelt, wirken sich
Veränderungen an der neuen Teil-Liste auch auf das Original aus.Die ArrayList speichert ihre Elemente intern in einem Array. Daher ist der Zugriff auf die einzelnen Elemente äußerst schnell. Allerdings sind Änderungen an der ArrayList umso aufwendiger, da immer alle nachfolgenden Listenelement verschoben werden müssen (außer das Element wird am Ende der Liste eingefügt bzw. gelöscht). Falls die Größe des internen Arrays nicht ausreicht, muss ein neues Array erzeugt und alle Elemente müssen umkopiert werden. Es gelten also alle Nachteile für Arrays auch für die ArrayList - nur dass sie dank der Einbindung in das Collections-Framework deutlich komfortabler zu programmieren ist als ein herkömmliches Array.
Die LinkedList ist als doppelt verkettete Liste realisiert. Eine solche Liste besteht aus Objekten, die jeweils eine
Referenz auf ihren Vorgänger und ihren Nachfolger halten.

Weil die LinkedList ohne einen Index arbeitet, muss bei einem wahlfreien Zugriff auf ein beliebiges Element im schlimmsten Fall
die ganze Liste durchlaufen werden, um eine Referenz auf das benötigte Element zu erhalten. Daher ist ein solcher Zugriff
bei der verketteten Liste langsamer, als bei der ArrayList. Stattdessen ist es deutlich schneller, ein Element an einer
beliebigen Stelle einzufügen oder zu löschen, da lediglich die Referenzen der Vorgänger und Nachfolger angepasst
werden müssen.

Mengen-Datenstrukturen werden in Java durch das Interface java.util.Set definiert. Sie dienen zur Verwaltung von
zusammengehörigen Elementen, bei der die Reihenfolge keine Rolle spielt und in der keine doppelten Elemente vorkommen
dürfen. Genauer gesagt wird sichergestell, dass die folgende Bedingung nie für ein beliebiges Element-Paar x und y
gilt: x.equals(y) == true.
Beispiele für Implementierungen:
java.util.TreeSet (als Baum realisiert)java.util.HashSet (als Hash-Tabelle)Zusätzlich zu den Methoden des Collections-Interfaces bietet ein Set keine neuen Methoden an. Stattdessen werden in der API-Dokumentation in natürlicher Sprache verfasst Regeln festgehalten, die für die Implementierung gelten sollen. Wenn zum Beispiel beim Erzeugen eines neuen Set dem Konstruktor eine Collection übergeben wird, so muss sichergestellt sein, dass in der übergebenen Collection keine doppelten Elemente enthaten sind. Auch zur equals()-Methode werden besondere Regeln festgelegt: Im Gegensatz zur Definition im Interface Collection liefert die equals()-Methode eins Set nur genau dann true, wenn das übergebene Objekt ebenfalls ein Set ist, die beiden Sets die gleiche Anzahl an Elementen haben und jedes Element jeweils auch in dem anderen Set gefunden werden kann.
Das TreeSet sortiert intern alle Elemente in einer Datenstruktur ein, die wie ein Suchbaum aufgebaut ist. Auf diese Weise können alle wichtigen Operationen wie add, remove, contains selbst bei sehr großen Datenmengen noch mit vertretbarem Aufwand durchgeführt werden.
Das HashSet nutzt intern eine Hash-Tabelle. Dadurch ist ein konstanter Aufwand bei den oben genannten Operationen
sichergestellt (vorausgesetzt die Hash-Funktion besitzt eine gute Streuung). Die Geschwindigkeit beim lesenden Zugriff auf die
Elemente steht einem etwas höheren Aufwand beim schreibenden Zugriff gegenüber, da die Kosten zur Berechnung der
Hash-Funktion berücksichtigt werden müssen.
Folgende Mengenoperationen können auf ein Set leicht implementiert werden:


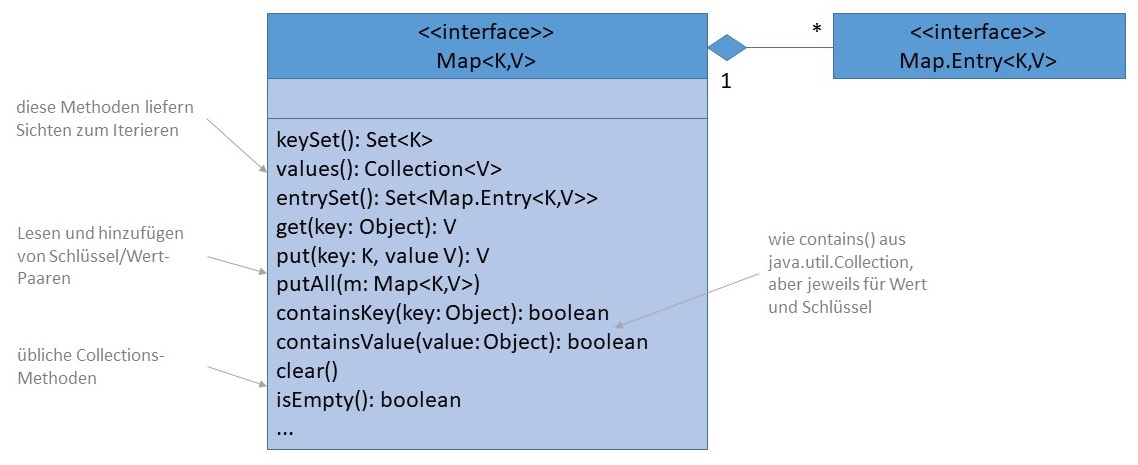
Die API-Dokumentation zum Interface java.util.Map verrät, dass es primäre Aufgabe dieser Datenstrukturen ist,
Schlüssel auf Werte (genauer: Objekte) abzubilden. Sie stellen also eine Assoziation zwischen dem Schlüssel und dem
Wert her, daher auch der in der deutschen Literatur gebrächliche Name "Assoziativspeicher" oder "assoziativer Speicher".
Die Kombination aus Schlüssel und Wert wird immer paarweise gespeichert und beide können beliebige Typen sein.
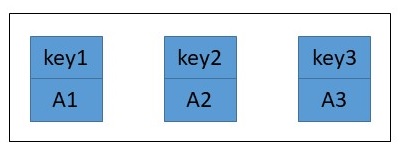
Beispiele für Implementierungen:
java.util.TreeMap (als Baum realisiert)java.util.HashMap (als Hash-Tabelle)java.util.LinkedHashMap (Kombination aus Hash-Tabelle und verketteter Liste)Map.Entry eingeführt: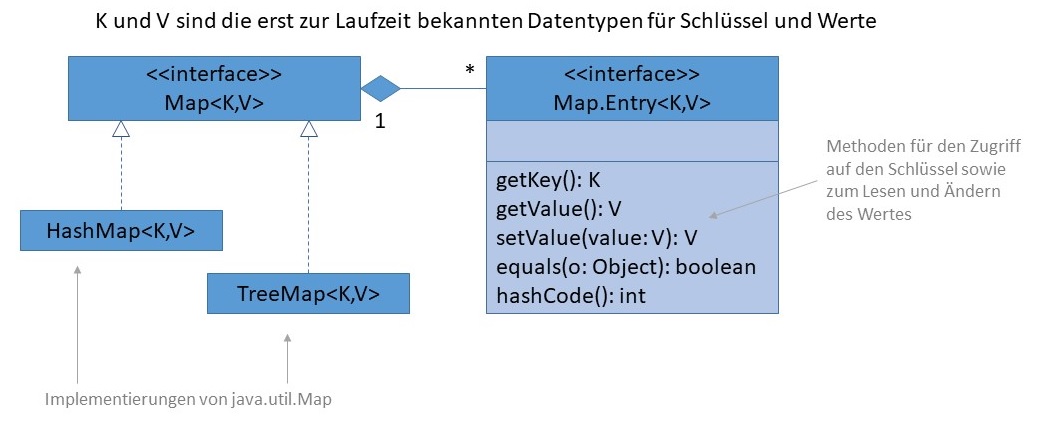
Für Maps gelten ein paar wichtige Regeln:
Weil sich die Art und Weise, wie Elemente in einer Map verwaltet werden, stark von den bisher behandelten Datenstrukturen des Collections-Framework unterscheidet, erbt das Interface Map nicht von Collection. Außerdem kann es nicht mit einem Iterator verwendet werden, denn es implementiert nicht das Interface Iterable. Stattdessen bietet das Interface spezielle Sichten auf die Elemente an, die z. B. das Iterieren über alle Schlüssel oder alle Werte erlaubt:
Set<K> keySet(): gibt ein Set mit allen Schlüsseln zurück.Collection<V> values(): gibt eine Collection mit allen Werten zurück.Set<Map.Entry<K,V>> entrySet(): gibt eine Menge zurück, die aus
den Schlüssel/Wert-Paaren der Map besteht.Darüber hinaus definiert das Interface weitere Methoden zur Verwaltung der Objekte. Sie orientieren sich hinsichtlich ihrer
Bezeichnung stets an das Collection-Interface, indem sie lediglich die Signatur um zusätzlich benötigte Informationen
wie den Schlüssel erweitern oder zusätzliche Methoden für den Schlüssel hinzufügen.
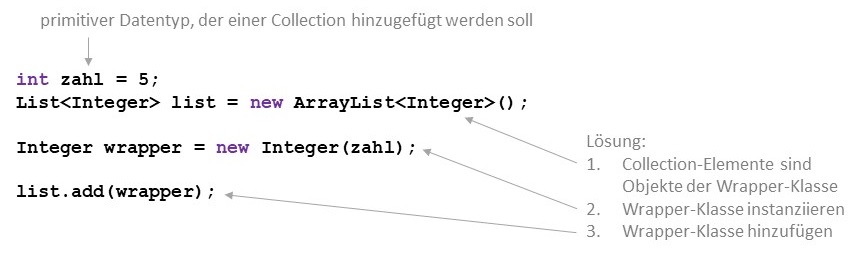
Collections haben eine tiefgreifende Einschränkung: Collections können grundsätzlich nur Referenzdatentypen speichern, keine primitiven Datentypen.
Wrapper-Klassen wurden in Java eingeführt, um primitive Datentypen wie Objekte behandeln zu können. Für jeden
primitiven Datentyp gibt es also eine entsprechende Wrapper-Klasse: Byte, Short, Integer, Long, Float,
Double und Char. Sie enthalten den Wert des primitiven Datentyps
und müssen wie jede andere Klasse auch instanziiert werden. Wrapper-Klassen sind zudem "immutable", das heißt sie können
nach der Instanziierung nicht mehr verändert werden; sie besitzen also keine setter-Methoden. Folgender Code zeigt, wie ein
primitiver Datentyp mithilfe einer Wrapper-Klasse einer Collection hinzugefügt werden kann.
Es stehen vier Implementierungen von Maps zur Auswahl: HashMap, TreeMap, LinkedHashMap und WeakHashMap.
Eine HashMap wird intern mit einer Hash-Tabelle implementiert. Der Speicherort eines einzufügenden Elements wird mit einer Typ-spezifischen Hash-Funktion (hashCode()) berechnet. Da Hash-Funkionen per Definition keine Sortierung unterstützen, sondern im Gegenteil versuchen, die Elemente möglichst breit auf den verfügbaren Speicherbereich zu verteilen, werden die Elemente einer HashMap intern nicht sortiert gespeichert. Weil die Datenstruktur "flach" ist, liegen die Vorteile einer HashMap in dem äußerst schnellen Zugriffsverfahren. Das Speichern hingegen dauert in der Regel etwas länger, da die Hash-Funktion mathematisch komplex ist.
Eine TreeMap speichert ihre Elemente in einer Baumstruktur, genauer gesagt in einem Suchbaum. Dabei wird anhand des Schlüssels einsortiert. Wenn man auf ein bestimmtes Element zugreifen möchte, muss man im schlimmsten Fall die gesamte "Tiefe" des Baumes durchlaufen, also von der Wurzel aus bis zu dem gesuchten Blatt. Auch wenn dieser Aufwand sehr gering ist, so ist er etwas höher als bei der HashMap. Umgekehrt lassen sich Elemente schneller einsortieren, da hierfür keine mathematisch aufwendige Funktion benötigt wird.
Die LinkedHashMap ist eine spezialisierte HashMap, die ihre Elemente in einer doppelt verketteten Liste speichert. Da hierbei die interne Ordnung entlang der Hash-Werte erfolgt, ist diese Variante insbesondere bei Anwendungsszenarien sinnvoll, wenn die Ordnung eine Rolle spielt.
Die WeakHashMap ist eine besondere Map, die der HashMap-Implementierung ähnelt. Sie arbeitet ebenfalls intern mit
einer Hash-Tabelle, jedoch darf die Laufzeitumgebung bei Speicherknappheit Elemente löschen.


Um eine "Undo"-Funktion implementieren zu können, muss eine Datenstruktur gefunden werden, die eine Historie
abbilden kann und zu der man stets das jüngste Ereignis anschauen kann bzw. ein nues Ereignis "obenauf" ablegen kann. Solche
Datenstrukturen werden oft "Stapel" (Stack) oder "Keller" genannt.
Beispiele für Implementierungen:
Interface java.util.Deque
java.util.ArrayDeque (als Array realisiert)java.util.Listjava.util.StackZwar bietet Java mit java.util.Stack und java.util.Deque
gleich zwei mögliche Datenstrukturen für diesen Anwendungsfall an, aber deren Design ist nicht wirklich
zufriedenstellend. Bis zu einer bestimmten Programmversion gab es nur die Datenstruktur Stack. Sie definiert einerseits
genau die Methoden, die von einem Stapel erwartet werden (Element auf den Stapel legen und vom Stapel herunternehmen). Andererseits
implementiert die Oberklasse Vector, auf die an dieser Stelle nicht weiter eingegangen wird, auch das Interface
java.util.List. Daher besitzt ein Stack auch eine Reihe anderer, für die
Datenstruktur untypische Methoden. Gleiches gilt für die Alternative
java.util.Deque, deren Implementierung ArrayDeque aktuell von den Entwicklern der Programmiersprache Java als
Stapel-Datenstruktur empfohlen wird.
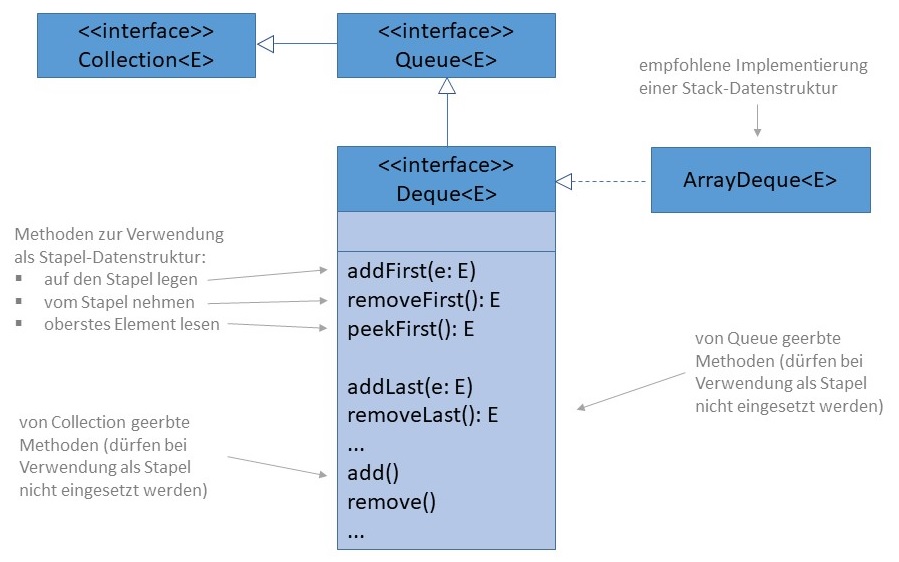
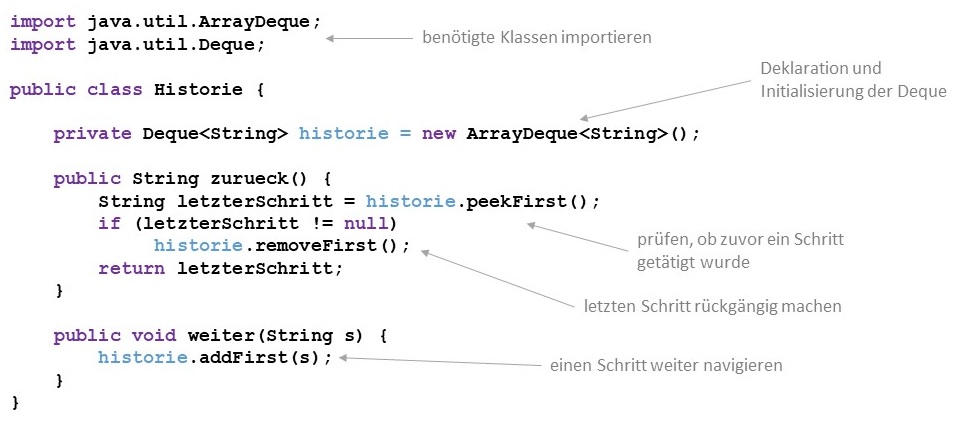
Die Umsetzung einer "Undo"-Funktion am Beispiel einer Historie für einen Bestellprozess. Wenn der Benutzer im Bestellprozess
fortfährt, wird der Schritt mit addFirst() auf den Stapel gelegt, Wenn der Benutzer einen Prozessschritt rückgängig
machen möchte, wird zuerst mit peekFirst() geprüft, ob überhaupt vorher ein Schritt getätigt wurde bzw. ob
der Benutzer sich noch im ersten Schritt befindet. Fall sich der Benuzer nicht im ersten Schritt befindet, wird der vorherige
Schritt mit removeFirst() vom Stapel genommen.
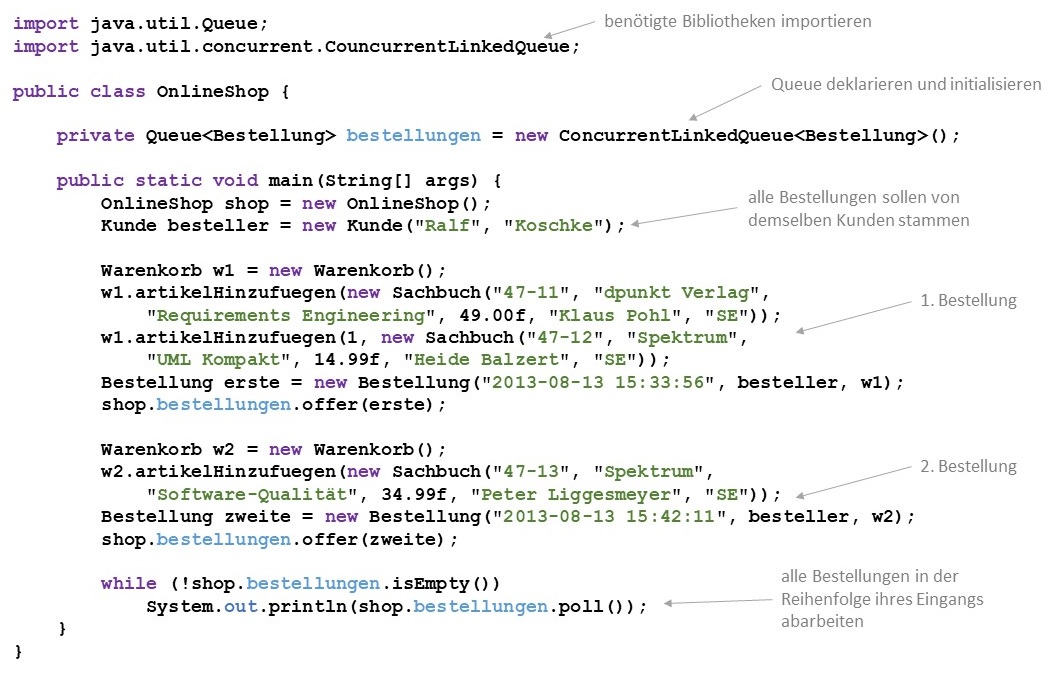
Queues ermöglichen die Bearbeitung der Objekte in der Reihenfolge ihres Eingangs.
Beispiele für Implementierungen:
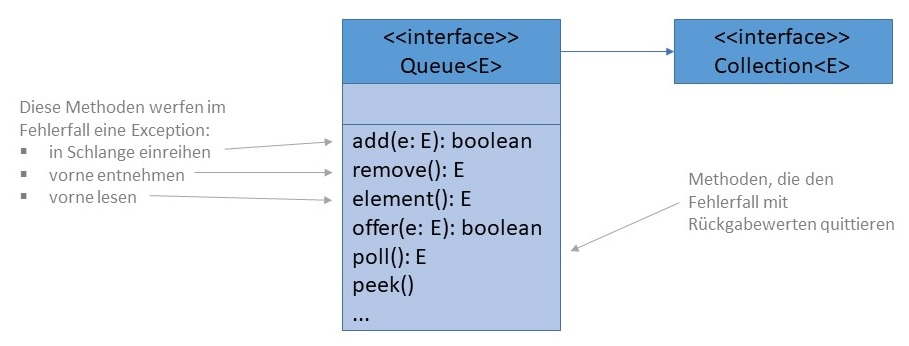
java.util.LinkedListFür alle drei Standard-Methoden (Hinzufügen, Löschen, oberstes Element abfragen) gibt es zwei Alternativen. Die
Methoden add(), remove() und element()
werfen im Fehlerfall (Speicher voll bzw. Queue leer) eine Exception, wohingegen offer(),
poll() und peek() den Fehlerfall mit einem entsprechenden
Rückgabewert quittieren.
Bei der Durchsicht der möglichen Implementierungen einer Queue zeigt sich schnell, dass sich hier die Entwickler der
Programmiersprache besonders viel Mühe gegeben haben. Um die Implementierungen sinnvoll gegenüberstellen zu können,
müssen auch die einzelnen spezialisierten Interfaces bekannt gemacht werden.
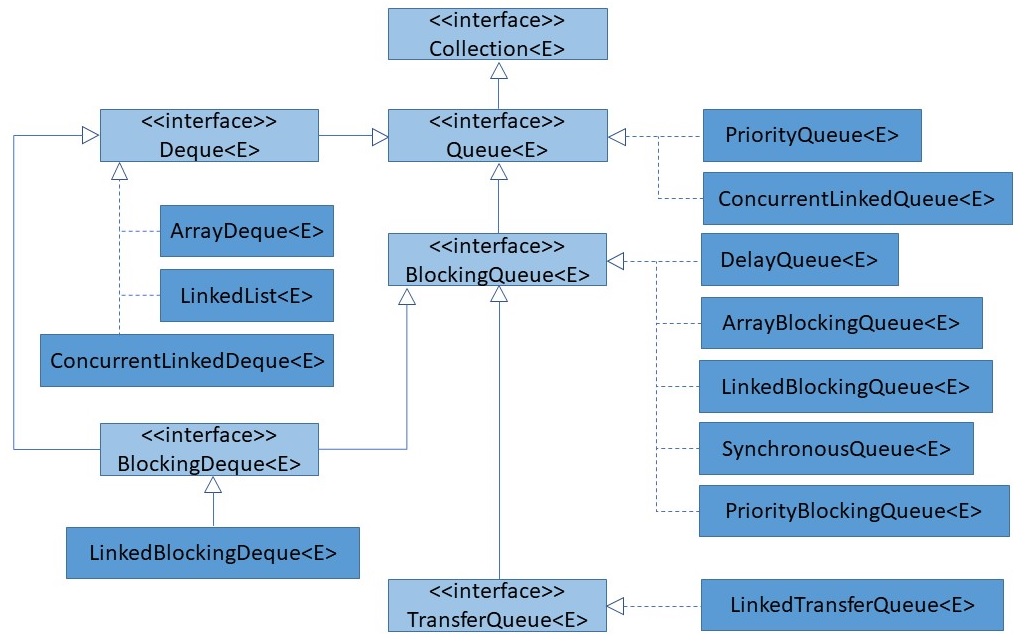
Zwei Klassen implementieren die Schnittstelle unmittelbar: PriorityQueue und
ConcurrentLinkedQueue. Erstere sortiert neue Elemente nicht nach der Reihefolge des
Eingangs ein, sondern anhand einer Priorität, die durch ein bestimmtes Attribut repräsentiert wird. Letztere implementiert
eine übliche Queue, die allerdings intern als einfach verkettete Liste gespeichert wird und im Zusammenhang mit parallelen
Programmfäden (Threads) genutzt werden kann.
Hinzu kommen die Implementierungen des Interfaces Deque, die aufgrund der
Vererbungsbeziehung zwischen Deque und Queue
ebenfalls als Queue eingesetzt werden können. Hierzu zählen u.a. die beiden
Klassen "LinkedList" und "ArrayDeque". Einen großen Anteil der Queue-Implementierungen machen die
BlockingQueues aus. Sie haben die besondere Eigenschat gemein, dass sie in einen Wartezustand wechseln, falls
kein Speicherplatz verfügbar ist, oder ein anderer paralleler Programmfaden auf die Queue zugreift.
Eine Klasse "Bestellung" könnte so als Queue implementiert werden: