Die Java-Klassenbibliothek beinhaltet alle wichtigen Klassen für den Umgang mit dem Dateisystem, Verzeichnissen und Dateien
im Paket java.io. Die wichtigste Klasse in diesem Paket ist die Klasse "File".
Dateisysteme sind im Allgemeinen hierarchisch aus Verzeichnissen und Dateien aufgebaut. Ausgehend von einem obersten Verzeichnis,
dem Wurzelverzeichnis, sind alle Verzeichnisse oder Dateien wiederum in anderen Verzeichnissen enthalten. Durch die Angabe eines
Pfades kann ein Verzeichnis oder eine Datei in der Dateisystemhierarchie eindeutig verortet werden.

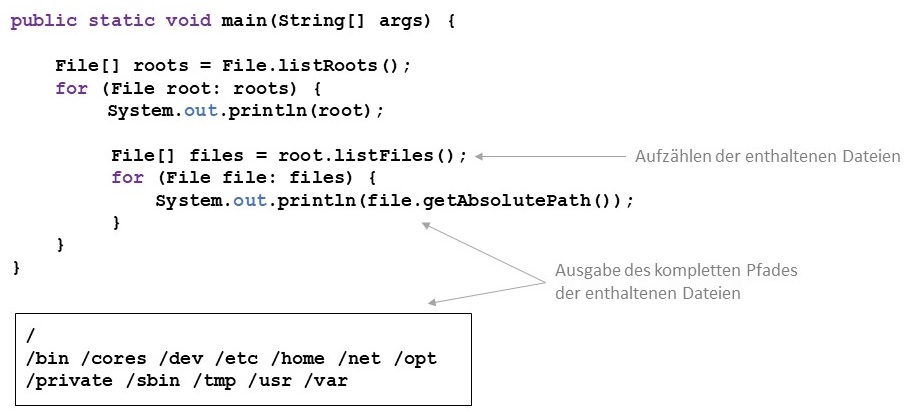
Die Klasse "File" repräsentiert in Java sowohl Verzeichnisse als auch Dateien. Mit der statischen Methode
listRoots lassen sich die Wurzelverzeichnisse auflisten. Der Aufruf von listRoots gibt
einen Array mit File-Objekten zurück, die die vorhandenen Wurzelverzeichnisse darstellen. Da es in Unix nur ein
Wurzelverzeichnis gibt, wird nur ein einzelner Slash (/) ausgegeben. Für ein Windows-System erhält man die Namen der
angeschlossenen Laufwerke (A:, B: etc.).

Die von listRoots zurückgegebenen File-Objekte stellen Verzeichnisse dar. Mittels der Methode
listFiles lassen sich die in den Verzeichnissen enthaltenen Untervereichnisse und
Dateien aufzählen.
Der Pfad einer Datei bzw. eines Verzeichnisses ist die textuelle Repräsentation seines Platzes in der Dateisystemhierarchie.
Der Pfad setzt sich dabei aus den Namen der Verzeichnisse zusammen, in denen die Datei bzw. das Verzeichnis enthalten ist,
angefangen vom Wurzelverzeichnis.
Ein Dateisystempfad ist nichts anderes als eine spezielle formatierte Zeichenkette. Die einzelnen Hierarchiestufen werden
durch ein Zeichen markiert, das die Namen der einzelnen Elemente voneinander trennt. In Linux-/Unix-Systemen ist dieses
Trennzeichen ein Slash (/), unter Windows ist das Trennzeichen ein Backslash (\). Damit man Java-Code schreiben kann, der unter all
diesen Betriebssystemen läuft, muss man also darauf achten, stets das richtige Hierarchietrennzeichen zu verwenden. Java
bietet zu diesem Zweck eine Klassenkonstante an, mit der man sich die Arbeit vereinfachen kann. Die Konstante
File.separator beinhaltet je nach ausführende Betriebssystem das richtige Zeichen.

Ein Pfad kann eine beliebige Zeichenkette sein. Erst beim Erzeugen eines File-Objektes mit diesem Pfad wird eine Beziehung zum
Dateisystem hergestellt und die durch den Pfad bezeichnete Datei bzw. das Verzeichnis manipulierbar. Nach dem Erzeugen können
über das File-Objekt Informationen abgefragt werden, z.B. ob das durch den Pfad bezeichnete Element existiert, ob es eine
Datei oder ein Verzeichnis ist, ob es erlaubt ist, es zu lesen, oder zu verändern, wann das Element zuletzt verändert
wurde usw.

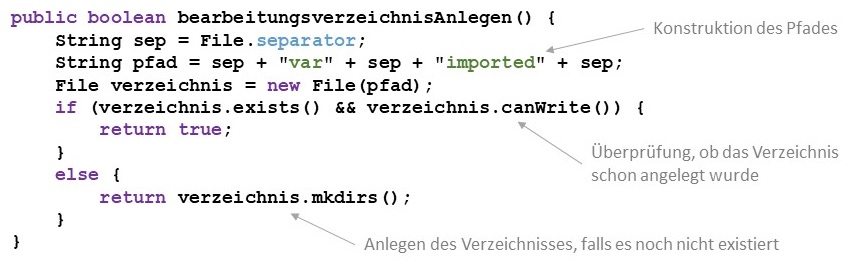
Man kann ein File-Objekt auch mit einem Pfad erzeugen, der noch nicht in der Dateisystemhierarchie existiert. Das ist dann wichtig,
wenn man neue Verzeichnisse anlegen möchte. Für das Anlegen von neuen Verzeichnissen stellen File-Objekte die Methoden
mkdir und mkdirs zur Verfügung. Die
Methode mkdir legt ein Verzeichnis an. Durch den Pfad des File-Objektes wird angegeben, an welcher Stelle in der Hierarchie es
angelegt wird. Die Methode mkdirs legt die ganze im Pfad benannte Verzeichnishierarchie an, erstellt also unter Umständen
mehr als ein Verzeichnis. Beide Methoden zeigen über ihren Rückgabewert an, ob die Operation erfolgreich war.
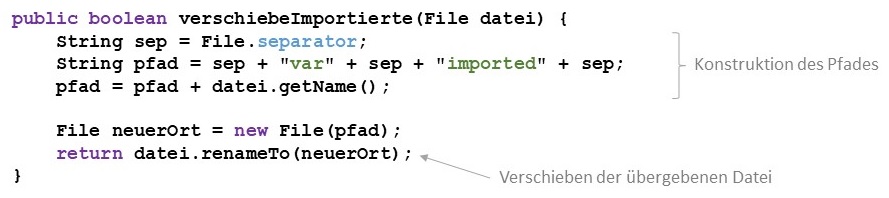
Die Klasse "File" bietet keine spezielle move-Methode an, um Dateien zu verschieben. Stattdessen kann man sich aber der Methode
renameTo bedienen, um durch das Umbenennen einer Datei ihren Ort in der
Dateisystemhierarchie zu verändern. Mittels der Methode getName kann zuerst der Name der Datei ermittelt werden, um damit
einen neuen Dateipfad zusammenzustellen, an dem die Datei liegen soll. Die Umbenennung wird dann mittels der Methode renameTo
durchgeführt. Der Rückgabewert gibt an, ob das Verschieben erfolgreich verlaufen ist.
| Vertiefende Information |
Die neuesten Java-Versionen (> 1.8) beinhalten in der Klassenbibliothek Klassen, mit denen die Arbeit mit dem Dateisystem
noch komfortabler gestaltet wird. Das Paket java.nio.file bietet unter anderem eine
Klasse zur Behandlung von Pfadangaben (java.nio.file.Paths) und eine Klasse, mit
der sich Verschiebe-, Umbenennungs- und Kopieroperationen komfortabler ausdrücken lassen
(java.nio.file.Files). Die Dokumentation ist als Javadoc im Internet zu finden.
|
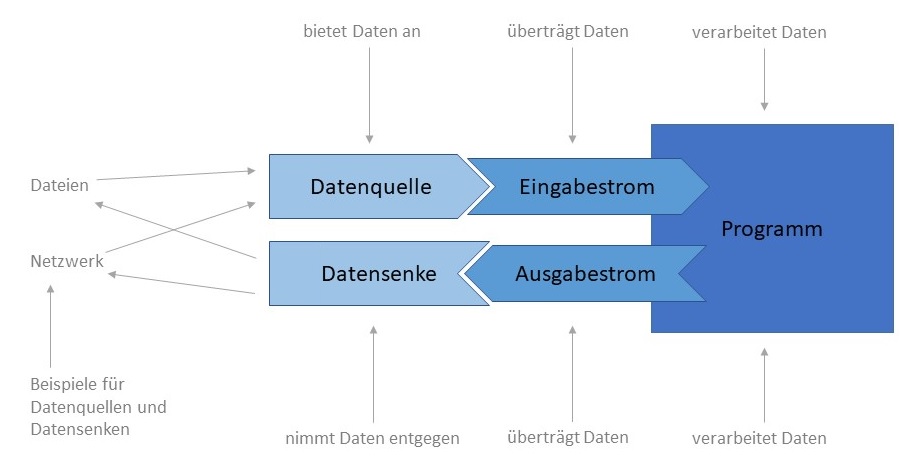
Die Arbeit mit Dateien ist in Java durch das Konzept der Datenströme abstrahiert. Ein Datenstrom bietet eine allgemeine
Schnittstelle für das Lesen und Schreiben von beliebigen Daten über beliebige Ein- und Ausgabemöglichkeiten. Die
Eingabemöglichkeiten nennt man auch Datenquellen, die Ausgabemöglichkeiten heißen auch Datensenken. Zwischen
einer Datenquelle und dem eigenen Programm verläuft ein Eingabestrom, über den Daten aus der Quelle in das
Programm gelangen. In der anderen Richtung (zwischen dem Programm und der Datensenke) verläuft ein Ausgabestrom, über
den Daten aus dem eigenen Programm weitergegeben werden.
So können Dateien sowohl Datenquellen (wenn aus ihnen gelesen wird) als auch Datensenken sein (wenn in sie geschrieben wird).
Dasselbe gilt für die Kommunikation über ein Netzwerk: Daten werden über eine Netzwerkschnittstelle (Internet,
Bluetooth, USB) empfangen und gesendet.
Datenströme kapseln eine hauptsächliche Funktionalität: Daten aus einer Datenquelle lesen oder in eine Datensenke schreiben. Für die Programmierer sollen die weiteren Details verborgen bleiben. Sie sollen sich nicht darum kümmern müssen, welche technischen Details für das Versenden von Daten zwischen zwei, durch das Internet verbundenen Computer einzuhalten sind. Die Programmierer schreiben Daten in einen Datenstrom, der die entsprechende Übertragung abstrahiert.
Java unterscheidet zwei wesentliche Arten von Datenströmen, und zwar zeichenorientierte und byteorientierte Datenströme. Zeichenorientierte Datenströme interpretieren die übermittelten Daten als einzelne Zeichen (chars) und sind daher gut für das Lesen und Schreiben von Textdaten geeignet. Byteorientierte Datenströme hingegen interpretieren die übermittelten Daten nicht als Zeichen, sondern als Bytes, weswegen sie für die Verarbeitung von Binärdaten wie zum Beispiel Bild-, Audio- oder Videodateien gedacht sind.
Die vier Datenstrom-Oberklassen aus der Java-Klassenbibliothek:
| Zeichenorientiert | Byteorientiert | |
| Eingabe | java.io.Reader(und Unterklassen) |
java.io.InputStream (und Unterklassen) |
| Ausgabe | java.io.Writer(und Unterklassen) |
java.io.OutputStream(und Unterklassen) |
Alle Klassen aus der Tabelle sind abstrakte Klassen, die die allgemeine Schnittstelle von Datenströmen definieren.
Die Java-Klassenbibliothek binhaltet entsprechende Unterklassen, mit denen konkrete Anwendungsfälle umgesetzt werden
können. Folgende Abbildung zeigt einen Ausschnitt der Hierarchie der Datenstromklassen. Die beiden Oberklassen
"InputStream" und "OutputStream" vereinigen Klassen, die hauptsächlich für die Verarbeitung von Binärdaten
verwendet werden. Die beiden Oberklassen "Reader" und "Writer" verarbeiten Textdaten.

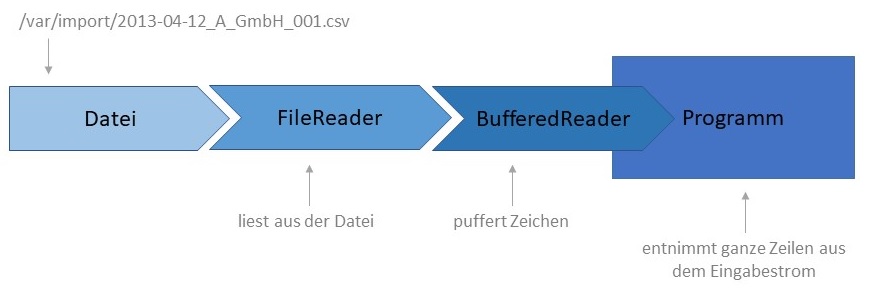
Die Klasse "java.io.BufferedReader" bietet eine Methode readLine, die aus einem
Datenstrom eine ganze Zeile entnimmt und zurückgibt. Um immer eine ganze Zeile zurückgeben zu können, puffert
ein BufferedReader-Objekt die Zeichen eines Eingabestroms, bis es auf einen Zeilenumbruch stößt. Ein
BufferedReader-Objekt kann nicht direkt aus Dateien lesen, daher muss noch ein Dateilesestrom erzeugt werden, wenn aus einer
Datei gelesen werden soll. Diese Dateilesestrom kann einem BufferedReader-Objekt zum Lesen übergeben werden.
Die Klasse "java.io.FileReader" stellt einen solchen Dateilesestrom zur Verfügung. Folgende Abbildung zeigt wie die
einzelnen Objekte zu einer sogenannten Pipeline verbunden sind und Daten aus einer Datei in das Programm liefern.
Es muss darauf geachtet werden, eventuell auftretende Ausnahmen zu behanden. Beim Erzeugen des FileReader-Objektes kann eine
FileNotFoundException geworfen werden, falls die Datei, die gelesen werden soll,
nicht existiert. Des Weiteren kann beim Aufrufen der readLine-Methode oder beim
Schließen der Datenströme eine IOException geworfen werden, die auf einen
Fehler bei der Verarbeitung des Eingabestroms hinweist.
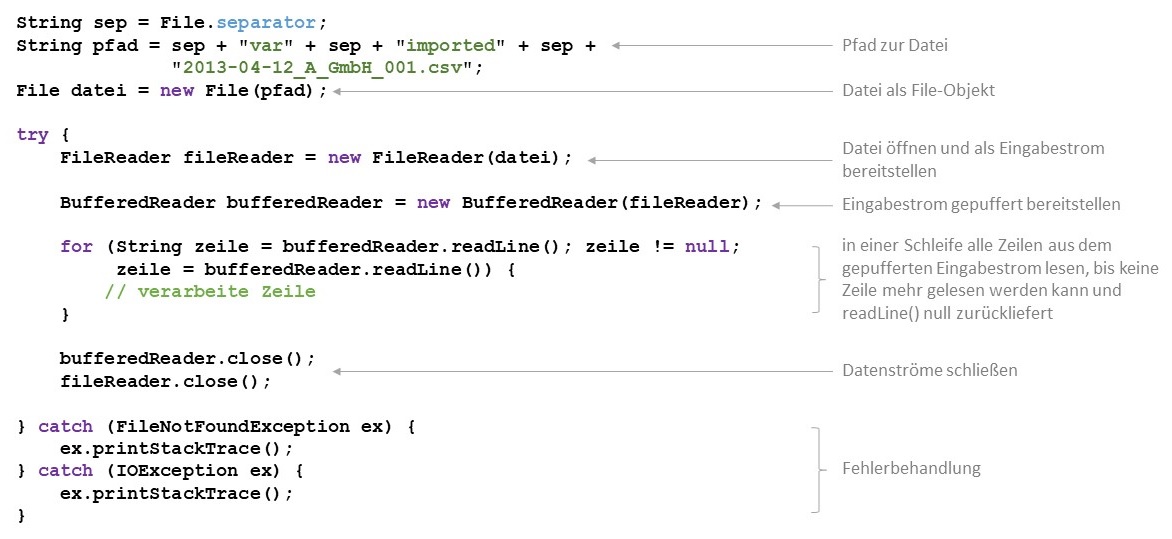
Nach dem Zugriff müssen alle Datenströme wieder geschloseen werden (close-Methode), damit die verwendeten Systemressourcen (wie zum Beispiel der vom BufferedReader verwendete Puffer) wieder freigegeben werden.
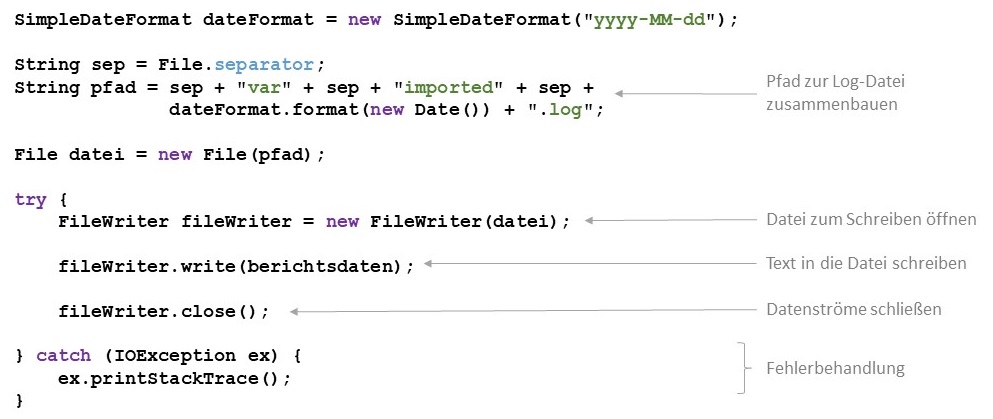
Zum Erzeugen eines File-Objektes für das Schreiben in eine Datei wird ein FileWriter-Objekt instaziiert und das
File-Objekt im Konstruktor übergeben. Die durch das File-Objekt bezeichnete Datei wird dadurch erstellt und zum Schreiben
geöffnet. Sollte die Datei bereits existieren, wird sie überschrieben, es wird kein Fehler ausgegeben. Mittels der
write-Methode des FileWriter-Objektes wird in die Datei geschrieben. Danach muss der Datenstrom mit der close-Methode
geschlossen werden. Das Aufrufen von close stellt sicher, dass auch Zeichen, die das FileWriter-Objekt aus Performancegründen
gepuffert hat, in die Datei geschrieben werden. Beim Öffnen, Schreiben und Schließen von Dateien können IOExceptions
auftreten, die entsprechend aufgefangen werden müssen.
Das Umkopieren einer Textdatei kann auch so erfolgen, indem zuerst die Zieldatei angelegt wird. Danach können in einer Schleife
alle Zeichen einzeln aus der Originaldatei mit der read-Methode gelesen werden. Ist kein Zeichen mehr zu lesen, gibt die
read-Methode -1 zurück.
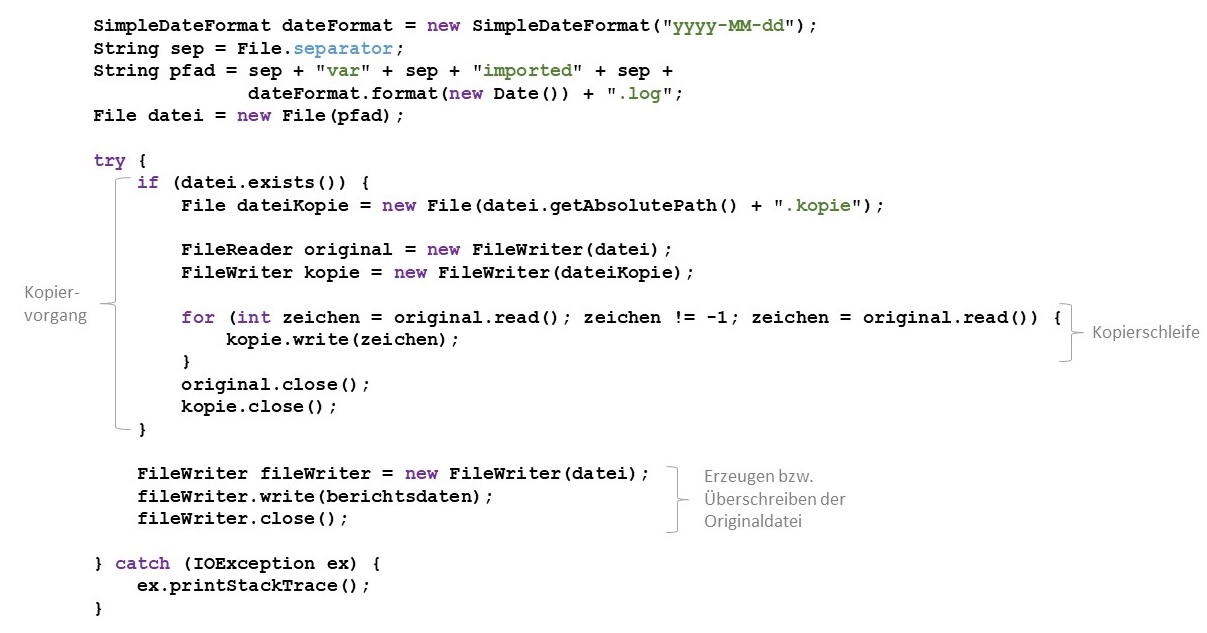
Das Konzept der Datenströme ist sehr mächtig. Jeder konkrete Datenstrom hat eine festgelegte Aufgabe und kommuniziert
über eine festgelegte Schnittstelle mit anderen Datenströmen. Diese allgemeine Schnittstelle erlaubt es auch,
Datenströme miteinander zu kombinieren. Mit den richtigen Datenströmen können so zum Beispiel Daten komprimiert
und dekomprimiert (Deflater/InflaterInputStream) oder verschlüsselt
(CypherInputStream, CypherOutputStream) werden. Alles, was es braucht, ist eine
entsprechende Konfiguration der Verarbeitungspipeline. Die einzelnen Stufen der Pipeline wissen nur, wie sie selber Daten
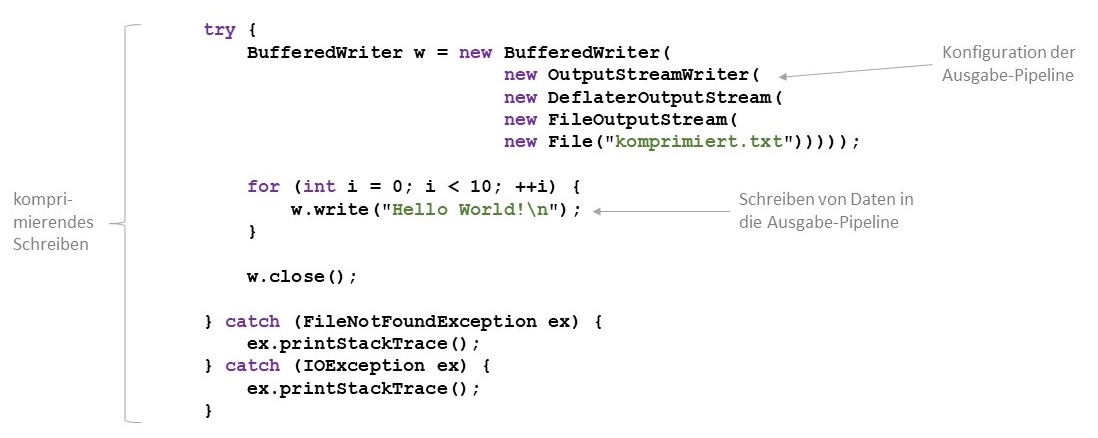
verarbeiten können und wohin sie die Daten nach der Bearbeitung übermitteln. Folgende Abbildung zeigt die
Konfiguration einer Pipeline für das Speichern und Lesen von komprimierten Dateien.
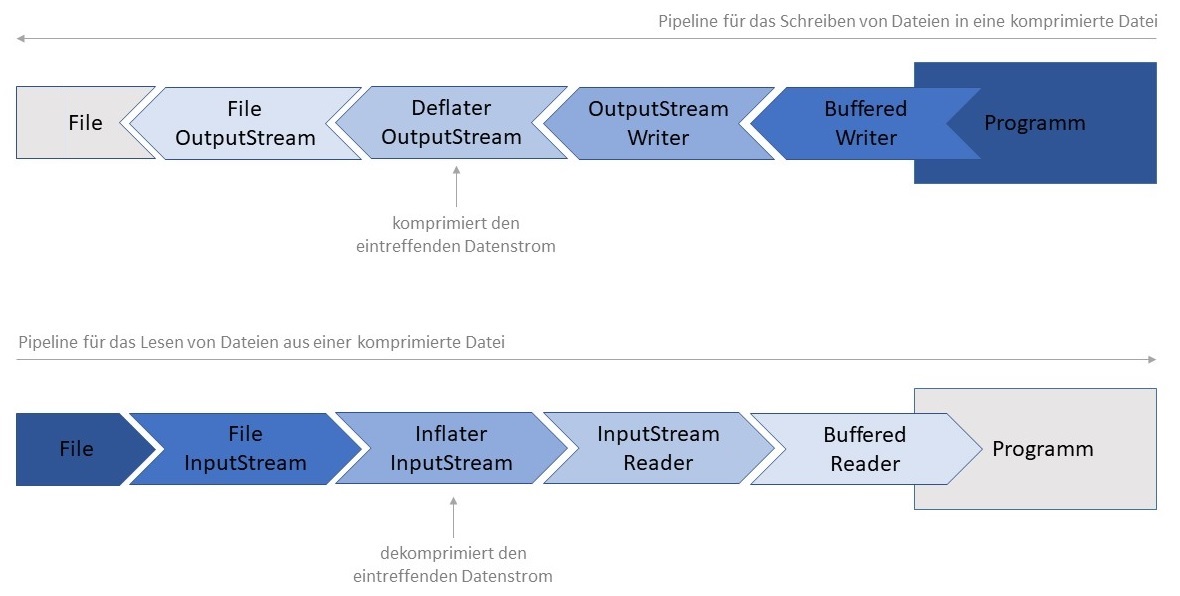
Bei der Erzeugung der Pipeline im Quellcode geht man immer vom Programm aus und schachtelt die entsprechenden Konstruktoren
von rechts nach links ineinander.