Um viele heterogene Datenformate in großen Mengen möglichst in Echtzeit verarbeiten zu können, bietet sich die Nutzung
sogenannter NoSQL-Datenbanksysteme (Not only SQL) an, die für die Kommunikation zwischen Server und Client nicht
ausschließlich SQL, sondern auch andere Protokolle benutzen. In klassischen, relationalen Datenbanksystemen (RDBM - Relational
Database Management Systems) werden Daten mithilfe einer Sammlung von Tabellen bestehend aus Zeilen (Datensätze) und
Spalten (Attribute) gespeichert. Jeder Datensatz ist hierbei über eine eindeutige, unveränderliche Schlüsselspalte
= Primärschlüssel (primary key, PK) identifizierbar. Dieser Primärschlüssel kann als sogenannter
Fremdschlüssel (foreign key, FK) in eine andere Tabelle übernommen werden, um Beziehungen (Relationen) zwischen Tabellen
abbilden zu können.
Nachfolgendes Beispiel verdeutlicht diesen Zusammenhang:
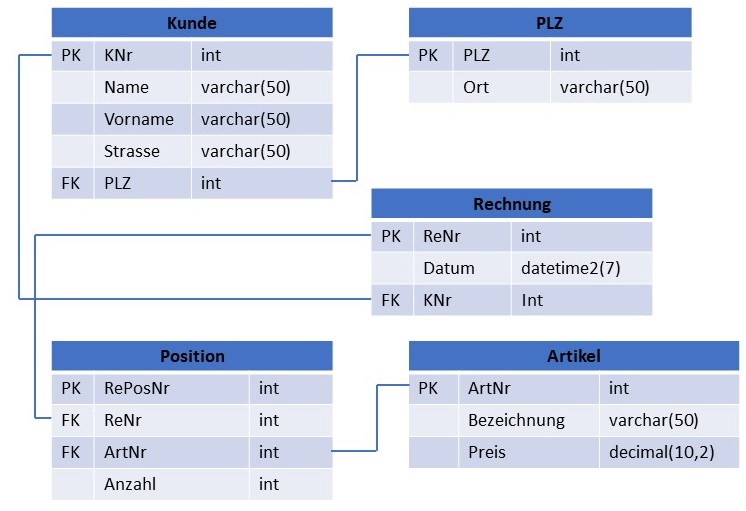
Sollen nun viele unterschiedliche Datenformate wie z.B. Bilder, Videos, Audiodaten und Texte in einer Datenbank gespeichert, evtl. durch den Nutzer mit Kommentaren versehen und z.B. mittels einer Webapplikation in einem gemeinsamen Kontext präsentiert werden, führt dies dazu, dass diese in unterschiedlichen Tabellen gespeicherten Daten über viele Relationen miteinander verbunden und ausgelesen werden müssen.
Dies erhöht einerseits die Komplexität beim Design einer solchen Datenbankstruktur und führt andererseits zu vielen Datenbankabfragen, die die Performance einer Applikation negativ beeinträchtigen.
Relationale Datenbanken sind für kleine Transaktionen (Schreibzugriffe) bei relativ statischen Datenbeständen ausgelegt und nicht für große Datenmengen, die sich dynamisch verändern.
NoSQL-Datenbanksysteme hingegen verzichten auf starre Datenbankstrukturen und speichern Daten ohne festes Schema so ab, dass der Zugriff auf diese Daten deutlich performanter erfolgen kann, als das bei relationalen Datenbanksystemen möglich wäre. Jedoch verwenden NoSQL- und relationale Datenbanksysteme unterschiedliche Konsistenzmodelle. Relationale Datenbanken achten sehr streng auf die Konsistenz ihrer Datenbestände und verwenden häufig das sogenannte ACID-Modell (atomicity, consistency, isolation und durability) als Kriterium für erwünschte Voraussetzungen verlässlicher Datenbanksysteme. NoSQL-Datenbanken hingegen orientieren sich häufig am sogenannten BASE-Modell, welches die Konsistenz zugunsten der Verfügbarkeit in den Hintergrund stellt:
Die Vorteile des BASE-Ansatzes zeigen sich vor allem beim Einsatz verteilter Datenbanksysteme. ACID-basierte, relationale Datenbanksysteme müssen für einen Schreibzugriff alle verteilten Datenbanken für andere Zugriffe kurzzeitig sperren. Beim BASE-Ansatz kann man auf solche Sperren verzichten. Die Verfügbarkeit verteilter Daten ist also auch während Schreibvorgängen sichergestellt.
Je nach Art der Datenspeicherung unterscheidet man bei NoSQL in dokumentenorientierte Datenbanken, Graphdatenbanken, Key Value-Datenbanken und spaltenorientierte Datenbanken. In einer dokumentenorientierten NoSQL-Datenbank würden unterschiedliche multimediale Inhalte wie folgt dargestellt werden:
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["http://myfirstimage.png","http://mysecondimage.png"],
"videos":[
{"url":"http://myfirstvideo.mp4","title":"The first video"},
{"url":"http://mysecondvideo.mp4","title":"The second video"}]
"audios":[
{"url":"http://myfirstaudio.mp3","title":"The first audio"},
{"url":"http://mysecondaudio.mp3","title":"The second audio"}]
Um große, unstrukturierte und in einem verteilten System wie einer NoSQL-Datenbank gelagerte Datenmengen verarbeiten zu können, werden Verfahren wie MapReduce benötigt. MapReduce ist ein durch Google entwickeltes Programmiermodell, das die Verarbeitung und das Durchsuchen großer, verteilter Datenmengen (z.B. von sozialen Netzwerken) in einem Cluster ermöglicht. MapReduce kommt bei großen Datenmengen (ab mehreren Terabyte) zum Einsatz, um Daten zu strukturieren und zu durchsuchen. Das dem Verfahren zugrundeliegende namensgebende MapReduce-Konzept basiert auf den zwei zentralen Phasen (map und reduce), die zur Strukturierung der Daten angewendet werden.
Datenfluss im MapReduce-Verfahren:

In der Map-Phase erfolgt die Aufteilung der Eingabedatei auf mehrere Prozesse, die dann parallelisiert Zwischenergebnisse kalkulieren. Nachdem alle Map-Prozesse ordnungsgemäß beendet wurden, starten mehrere Reduce-Prozesse, die ebenfalls parallel Berechnungen starten, wobei jeder Prozess eine eigene Ausgabedatei erzeugt. Anwendungsfälle für MapReduce-Verfahren sind beispielsweise das Zählen einer Worthäufigkeit in einer Datei oder auch die Ermittlung von am häufigsten referenzierten Webseiten. Insbesondere Betreiber sozialer Netzwerke wie z.B. Facebook oder auch Websuchmaschinenbetreiber wie z.B. Google nutzen MapReduce-Verfahren zur Aufbereitung großer, dynamischer Datenmengen unterschiedlichster Formate.