Informationen im Web (z.B. Homepages, Portale) sind aktuell überwiegend so gestaltet, dass ein menschlicher Nutzer sie optimal erfassen und auswerten kann. Idealerweise werden bei der Gestaltung einschlägige Standards zu Ergonomie und Barrierefreiheit berücksichtigt. Maschinelle Nutzer wie z.B. Suchmaschinen können diese im Zeitverlauf sehr stark angewachsenen Datenmengen und heterogenen Datenformate (z.B. Text, Bilder, Videos) jedoch lediglich nach übereinstimmenden Zeichenketten durchsuchen. Beispielsweise führt eine Suchmaschinensuche nach dem Begriff "Hamburg" zu vielen unterschiedlichen Treffern. Ob nun der gewünschte Inhalt aus der Trefferliste die Stadt Hamburg, das Bundesland Hamburg oder ein Schiff namens Hamburg betrifft, erschließt sich dem menschlichen Nutzer aus dem Kontext der Information (z.B. weiterführender Text oder Bilder). Um eine einheitliche Aufbereitung und Auswertung dieser Informationen mittels automatisierter, maschineller Verfahren zu ermöglichen, muss dieser Kontext als weiterführende Information mit dem ursprünglichen Inhalt verknüpft werden.
Um im IoT große Datenmengen nicht nur einfach ablegen, sondern diese darüber hinaus auch in Beziehung zueinander bringen zu können, werden standardisierte Datenformate und Software Tools benötigt, um diese Daten managen zu können und im Web recherchierbar zu machen. Eine solche Ansammlung von in unterschiedlichster Weise miteinander in Beziehung stehenden, verknüpften Datensätzen im Web bezeichnet man auch als "Linked Data". Mithilfe von Linked Data werden Daten im Web nun nicht mehr in menschenlesbaren HTML-Dokumenten, sondern in maschinenlesbaren Strukturen veröffentlicht, die quasi wie eine einzige Datenbank behandelt werden können. Die nachfolgende Abbildung zeigt einen Ausschnitt der Gesamtheit aller Datensätze im Linked Data-Format, die der Linking Open Data Community durch Organisationen oder Personen zur Verfügung gestellt wurden.

Das DBPedia-Projekt im Zentrum der Linked Data-Aktivitäten hat es sich zur Aufgabe gemacht, Informationen aus Wikipedia zu extrahieren und der Allgemeinheit unter einer Open Source-Lizenz zur Verfügung zu stellen.
Aktuell werden in der englischen Version von DBPedia ca. 4,6 Millionen Datensätze (Personen, Organisationen, Filme etc.) zum Abruf bereitgestellt.
Daten im Web werden heutzutage hauptsächlich in Form von verlinkten HTML-Dokumenten veröffentlicht, die von Menschen gelesen werden können. Maschinen (Applikationen) können diese Dokumente zwar nach Schlüsselwörtern durchsuchen (Suchmaschinen wie z.B. Google oder Yahoo), diese jedoch nicht in einen sinnvollen Kontext bringen. Möchte man diese Daten nun mit eigenen Applikationen verarbeiten oder austauschen, dann müssen entsprechende Schnittstellen erstellt oder die Daten in ein passendes Format überführt werden.
Um zeitaufwendige Konversionen zu vermeiden und um ein einheitliches Format für den Datenaustausch nutzen und für
Linked Data erstellen zu können, wurde durch das W3C (World Wide Web Consortium) im Jahr 2014 der RDF-Standard (Resource
Description Framework) entwickelt. RDF beschreibt ein Datenmodell, das auf einer graphenorientierten Datenbank basiert und
inhaltliche Metadaten darstellt. Eine graphenorientierte Datenbank besteht aus einer Ressource, die Beziehungen zu anderen
Ressourcen hat. Das nachfolgende Diagramm stellt ein einfaches Beispiel für eine graphenorientierte Datenbank dar. Die
beiden Ressourcen Susi und Paul repräsentieren Menschen und die Eigenschaften Hass und Liebe die Beziehung des jeweiligen
Typs (lieben, hassen) zwischen diesen beiden Menschen.
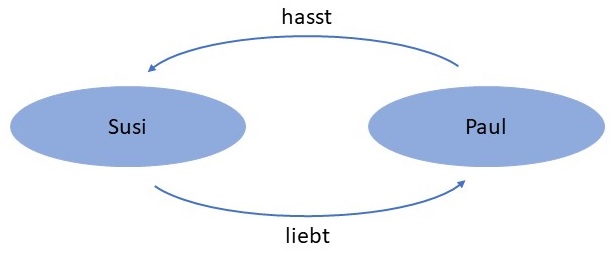
RDF, als ein standardisiertes Datenformat um graphenorientierte Datenbanken erstellen zu können, basiert auf sogenannten Statements. Ein RDF-Statement besteht aus den drei Elementen Subjekt, Prädikat (Beziehung) und Objekt. Die Kombination dieser drei Elemente wird auch als RDF-Tripel bezeichnet. RDF-Tripel sind somit die grundlegenden Bausteine für graphenorientierte Datenbanken.
Bezogen auf das in der obigen Abbildung dargestellte Beispiel stellt sich das RDF-Statement hierfür wie folgt dar:
| Beispielhaftes RDF-Statement 1 | ||
|---|---|---|
| Subjekt | Prädikat | Objekt |
| Susi | liebt | Paul |
| Paul | hasst | Susi |
Mittels RDF können zwar Aussagen (Statements) über einzelne Ressourcen, jedoch nicht über generische Mengen von Personen oder Organisationen (Klassen) definiert werden. Ebenso können keine logischen Zusammenhänge zwischen Ressourcen oder Klassen definiert werden.
RDFS (RDF-Schema) ist Teil der W3C-Empfehlungen zu RDF und beinhaltet genau diese fehlenden Funktionalitäten. RDFS stellt ein passendes Vokabular zur Verfügung, um mittels eines Klassenkonzeptes bestehend aus Klassen und Eigenschaften RDF-Elemente formal zu beschreiben. Anhand folgenden Fußballbeispiels soll dies verdeutlicht werden. Da RDFS sich der Syntax von RDF bedient, erfolgt die Darstellung als RDF-Statement.
| Beispielhaftes RDF-Statement 2 | ||
|---|---|---|
| Subjekt | Prädikat | Objekt |
| Spieler | rdfs:type | rdfs:Class |
| Trainer | rdfs:type | rdfs:Class |
Mithilfe des Konstrukts "rdfs:Class" werden zwei neue Klassen mit Namen "Spieler" und "Trainer" erzeugt, die bei einer maschinellen Auswertung direkt als Klassen identifizierbar sind.
| Beispielhaftes RDF-Statement 3 | ||
|---|---|---|
| Subjekt | Prädikat | Objekt |
| Abwehrspieler | rdfs:subClassOf | Spieler |
| Mats Hummels | rdfs:type | Abwehrspieler |
Das Konstrukt "rdfs:subClassOf" erlaubt es Unterklassen zu definieren und dadurch Klassenhierarchien zu ermöglichen, wodurch bei maschineller Auswertung neue Schlussfolgerungen möglich sind. Aus den gegebenen RDF-Statements kann somit automatisch abgeleitet werden, dass Mats Hummels ein Spieler ist. Anhand der Datenlage scheint Mats Hummels zwar kein Trainer zu sein, es lässt sich allerdings auch nicht ausschließen. In solchen Fällen kann eine graphbasierte Datenbank aufgrund des Prinzips der "open world assumption" keine Aussage ableiten.