Die bis jetzt durchgeführten Änderungen am Datenbestand waren dahingehend einfach, als sie sich nur auf eine einzige Tabelle bezogen. Wurden aber beispielsweise durch die Definition von Fremdschlüsseln Abhängigkeiten zwischen verschiedenen Tabellen festgelegt, muss beim Ändern des Datenbestands durch Einfügen, Ändern oder Löschen von Daten die Konsistenz gewährleistet werden. Das betrifft insbesondere die Gewährleistung der referentiellen Integrität.
Gefahren für die Konsistenz einer Datenbank lassen sich auf verschiedenen Ebenen identifizieren:
Bei all diesen möglichen Szenarien muss das Transaktionsmanagement eines DBMS verhindern, dass nicht vollständig ausgeführte
Operationen den Datenbestand verändern. Folgendes Beispielszenario veranschaulicht den Bedarf von Transaktionen: In den Datenbestand
eines Onlineshops sollen Artikel hinzugefügt werden. Das Datenschema dafür ist in der folgenden Abbildung dargestellt. Es handelt
sich dabei um eine Joined-Subclass-Table-Abbildung einer Vererbungshierarchie.
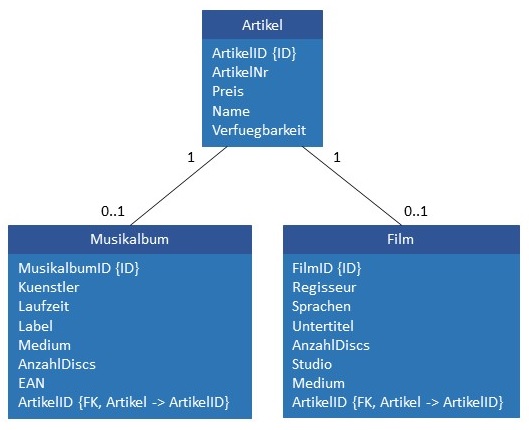
Dabei besteht ein Artikel aus zwei Datensätzen: Ein Datensatz in der Tabelle Artikel und ein Datensatz in der Tabelle Musikalbum bzw. der Tabelle Film. Soll ein Artikel in den Warenbestand ein- oder ausgelistet werden, so müssen immer zwei Datensätze zusammenhängend geändert werden:
INSERT INTO Musikalbum [...]
INSERT INTO Artikel [...]
Wird zum Beispiel aus einem der oben genannten Gründe nur das erste der beiden INSERT-Statements
ausgeführt, so würde in der Datenbank ein Datensatz Musikalbum ohne den korrespondierenden Datensatz Artikel existieren. Um das
zu verhindern, werden beide INSERT-Statements in eine Transaktion zusammengefasst.
Folgende Kriterien, auch ACID-Eigenschaften genannt, müssen durch eine Transaktion in einem DBMS erfüllt werden:
Eine einfache Möglichkeit mehrere SQL-Statements zu einer Transaktion zusammenzufassen, ist in der folgenden Abbildung dargestellt.
Das konkrete Schlüsselwort zum Start ist abhängig vom gewählten DBMS.

Das oben genannte Beispiel könnte wie folgt implementiert werden:
START TRANSACTION;
INSERT INTO Musikalbum [...]
INSERT INTO Artikel [...]
COMMIT;
Eine Transaktion beginnt mit START TRANSACTION und wird entweder mit dem Schlüsselwort
COMMIT oder dem Schlüsselwort ROLLBACK abgeschlossen. Mit
COMMIT werden alle Änderungen persistiert, mit ROLLBACK
werden alle Änderungen rückgängig gemacht. Wird während der Abarbeitung einer Transaktion ein Fehler erkannt, so kann
mit ROLLBACK der Zustand wiederhergestellt werden, den der Datenbestand vor Beginn der Transaktion
hatte.
| Hinweis |
In der Regel bieten DBMS die Option AUTOCOMMIT an. Wird das
AUTOCOMMIT aktiviert, wird jedes SQL-Statement einzeln automatisch als Transaktion
durchgeführt.
|
Industrielle Informationssysteme werden in der Regel nicht nur von einem, sondern von mehreren hundert bis mehreren tausend Nutzern gleichzeitig verwendet. Und alle Nutzer wollen gleichzeitig auch den in der Datenbank der Anwendung gespeicherten Datenbestand lesen und ändern. Folgende Herausforderung stellt sich dem Entwicklerteam: Sollen alle Transaktionseigenschaften garantiert werden, dann können die Aktionen aller Nutzer nur sequenziell, also nacheinander ausgeführt werden. Denn um sicherzustellen, dass sich Transaktionen nicht gegenseitig beeinflussen, müssten große Teile der Datenbank für Zugriffe gesperrt werden. Das führt allerdings häufig zu einem aus Sicht der Nutzer sehr langsamen und damit unbenutzbaren System. Soll jedoch der gleichzeitige Zugriff mehrerer Nutzer auf den Datenbestand gewährleistet werden, lassen sich sogenannte Isolationsphänomene nicht vermeiden. Als Isolationsphänomen werden Effekte bezeichnet, die beim gleichzeitigen Ausführen von jeweils in sich korrekten Transaktionen in einer Datenbank auftreten können. Die vier verschiedenen und im Folgenden vorgestellten Isolationsphänomene lassen sich wie folgt unterscheiden: Lost Update, Dirty Read (Temporary Update), Non-repeatable Read und Phantom Read.
Als Lost-Update-Phänomen werden Änderungen bezeichnet, die durch das nebenläufige Ausführen von Transaktionen auftreten.
Unter Nebenläufigkeit von mehreren Transaktionen versteht man, dass diese gleichzeitig (parallel) oder in beliebiger Reihenfolge
durchgeführt werden können. Die folgende Abbildung veranschaulicht das Lost-Update-Phänomen. Zwei an sich korrekte
Transaktionen werden aus Sicht der jeweiligen Anwendungen, wie links in der Abbildung dargestellt, ausgeführt. Im Zusammenspiel
(in der Abbildung rechts) wird die von Anwendung 1 durchgeführte Änderung jedoch von Anwendung 2 überschrieben, ohne dass
Anwendung 1 diese Änderungen bekannt werden.

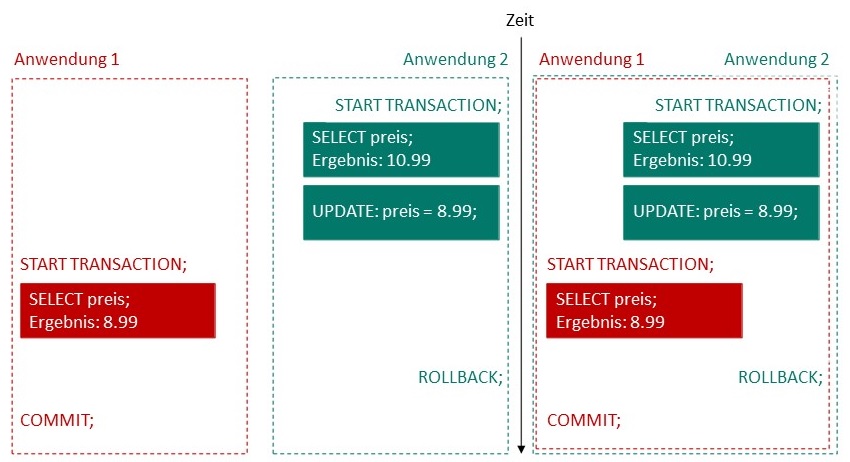
Das Phänomen Dirty Read wird in der folgenden Abbildung veranschaulicht. Es bezeichnet den Effekt, dass Änderungen gelesen werden,
noch bevor diese durch ein COMMIT auch tatsächlich in der Datenbank gespeichert werden. Werden, wie
im Beispiel dargestellt, mit einem ROLLBACK die Änderungen rückgängig gemacht, ist
Anwendung 1 ein niemals gültiger Preis bekannt.
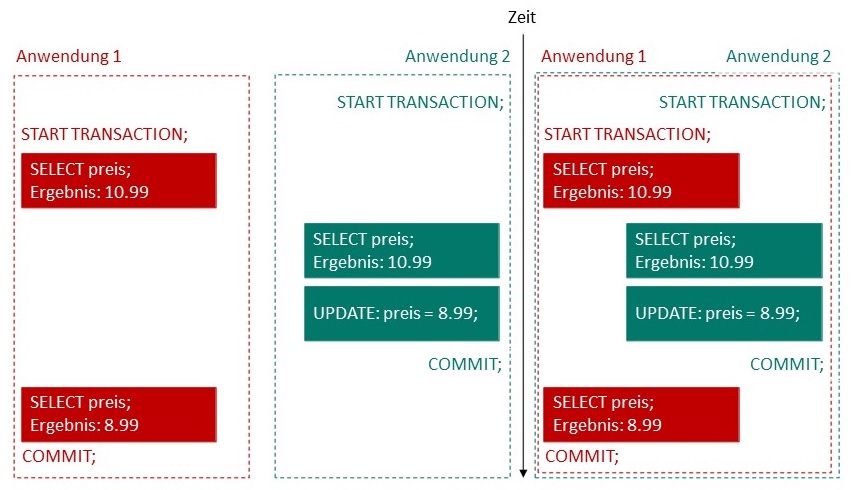
Das Phänomen Non-repeatable Read bezeichnet einen Effekt, bei dem ein mehrmaliges Lesen derselben Daten jeweils unterschiedliche
Ergebnisse zurückliefert. Wie im Beispiel der folgenden Abbildung veranschaulicht, wird ein Datensatz von Anwendung 1 mehrfach
ausgelesen. Die Änderung der Daten durch Anwendung 2 führt dabei zu unterschiedlichen Ergebnissen.
Das Phänomen Phantom Read bezeichnet unterschiedliche Ergebnisse beim Lesen derselben Tabellen, die durch das Einfügen
(INSERT) oder Löschen (DELETE) von Datensätzen der
Datenbank verursacht werden. Die folgende Abbildung illustriert diesen Effekt, bei dem beim ersten Lesezugriff von Anwendung 1 kein Element
in der Ergebnismenge enthalten ist, beim zweiten Lesezugriff jedoch schon.

SQL bietet die Möglichkeit für jede Transaktion ein bestimmtes Isolationslevel festzulegen, mit dem gezielt Isolationsphänomene zugelassen bzw. verboten werden. Auf diese Weise kann bei der Erstellung von Transaktionen ein Kompromiss zwischen Datenkonsistenz und Mehrnutzerbetrieb getroffen werden. Es können dabei vier Isolationslevel unterschieden werden: Read Uncommitted, Read Committed, Repeatable Read und Serialize. In der folgenden Tabelle werden die Isolationslevel beschrieben und angegeben, welche Isolationsphänomene durch sie zugelassen werden.
| Isolationslevel von Transaktionen | ||
|---|---|---|
| Isolationslevel | Beschreibung | Zugelassene Phänomene |
| Read Uncommitted | Niedrigstes Isolationslevel, bei dem auch nicht durch COMMIT bestätigteÄnderungen gelesen werden können. |
Lost Update, Dirty Read, Non-repeatable Read, Phantom Read |
| Read Committed | Erlaubt das Lesen nur von bereits durch COMMIT bestätigte Daten,verhindert jedoch keine Inkonsisten- zen bei mehrfachem Lesen. |
Non-repeatable Read, Phantom Read |
| Repeatable Read | Stellt sicher, dass beim mehrfachen Lesen des gleichen Datensatzes die gleichen Daten zur Verfügung stehen. Verhindert jedoch keine Abweichungen durch Einfügen oder Löschen. |
Phantom Read |
| Serialize | Stellt sicher, das beim mehrfachen Lesen innerhalb einer Transaktion jeweils immer die gleichen Daten- menge zur Verfügung steht. Verhindert somit alle Isolations- phänomene. |
keine |
Das Einstellen von Isolationslevel von Transaktionen entspricht einer kontrollierten Verletzung der Transaktionseigenschaft Isoliertheit, um einen effizienten Mehrbenutzerbetrieb von Datenbanken zu ermöglichen.