Kernprinzip der Datenorganisation
Das Prinzip der Datenorganisation von Key-Value-Systemen ist denkbar einfach: Zu einem Schlüssel (engl.: key) wird ein Wert (engl.:
value) gespeichert. Ein Wert kann dabei selber wieder eine Datenstruktur wie beispielsweise Listen oder Mengen sein. In der Programmiersprache
Java wird mit der Collection-Datenstruktur Map auch eine Key-Value-Speicherstruktur implementiert.
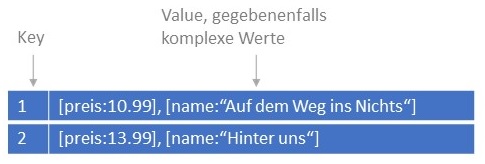
Durch das einfache Datenmodell von Key-Value-Systemen können große und stetig wachsende Datenmengen schnell und effizient organisiert werden, da keine schemabedingten Abhängigkeiten zwischen einzelnen Datensätzen existieren. Allerdings wird die Möglichkeit zur Formulierung von Abfragen auf einem Key-Value-System durch die API des Herstellers vorgegeben und daher die eigene Formulierung komplexer Abfragen häufig schwer oder gar nicht möglich.
Typische Vertreter
Kernprinzip der Datenorganisation
In Wide-Column-Store-Datenbanken werden die Daten zwar in Tabellen, jedoch anders als in relationalen Datenbanken spaltenweise statt
zeilenweise physikalisch gespeichert. Werden die Daten einer relationalen Datenbank zeilenweise gespeichert:
1, 10.99, "Auf dem Weg ins Nichts", 2, 13.99, "Hinter uns"
erfolgt die Speicherung von Daten in spaltenorientierten Systemen spaltenweise:
1, 2, 10.99, 13.99, "Auf dem Weg ins Nichts", "Hinter uns"
Auf diese Weise wird ein schnelles Lesen und Ändern ganzer Spalten ermöglicht, da alle Daten einer Spalte direkt hintereinander im
Speicher abgelegt werden. Darüber hinaus lassen sich Spalten zu sogenannten Familien gruppieren.
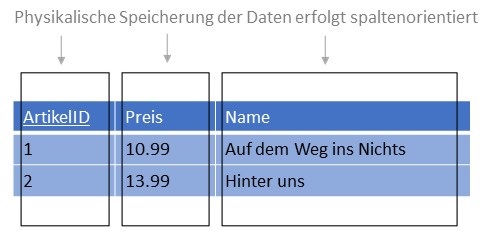
Mit der in der Abbildung dargestellten Spaltenorientierung werden analytische Funktionen sehr gut unterstützt, wie sie beispielsweise im Data-Warehouse-Umfeld zum Einsatz kommen. Auswertungsfunktionen, die sich auf ganze Spalten beziehen, wie Aggregatsfunktionen, werden durch diese Art der Speicherorganisation sehr gut unterstützt. Das Schreiben und Lesen von vollständigen Datensätzen ist hingegen aufwendiger, da zum vollständigen Lesen aller Daten zu einem Datensatz jeweils in verschiedenen Spaltendaten der passende Wert gesucht werden muss.
Typische Vertreter
Folgende DBMS basieren auf der Spaltenorientierung, erweitern dieses Konzept jedoch um Key-Value-Strukturen:
Kernprinzip der Datenorganisation
Document Stores speichern, anders als der Name es vielleicht suggeriert, keine Dokumente ab, die ein Anwender geschrieben hat. Der Begriff
Document bezeichnet, wie in der folgenden Abbildung veranschaulicht, strukturierten Text, wie beispielsweise XML oder JSON, der zum
Austausch von Nachrichten an technischen Systemschnittstellen eingesetzt wird. Oft wird durch das DBMS nur das Format von IDs vorgegeben,
jedoch kein festes Datenschema.

Vor- und Nachteil zugleich von Document Stores ist die vollständige Verlagerung der Verantwortung zur Einhaltung des erforderlichen Datenschemas in die Logik der Anwendung. Auf der einen Seite sind dokumentenbasierte Datenbanken schnell änderbar und jede Art von Daten kann sofort in ihnen gespeichert werden, jedoch müssen alle Konsistenzanforderungen ebenfalls von Anwendungslogik sichergestellt werden.
Typische Vertreter
Kernprinzip der Datenorganisation
Graphdatenbanken nutzen Graphen als die grundlegende Datenstruktur zur Organisation der in ihnen gespeicherten Information. Ein Graph besteht
aus den Knoten und Kanten, zu denen jeweils spezifische Eigenschaften gespeichert werden können. Informationen sind in vielen Fach-
und Wissensgebieten netzwerkartig strukturiert. Beispiele hierfür sind Beziehungsgraphen in sozialen Netzwerken, oder Bahn-, Straßen-
und Luftverkehrsnetze. Mit Graphdatenbanken können solche Beziehungen zwischen Elementen typisiert und in ihrer natürlichen Form
geseichert werden. Die folgende Abbildung veranschaulicht die Elemente in Graphdatenbanken anhand der Knotentypen Lieferant und Artikel,
die über eine Kante verbunden sind.
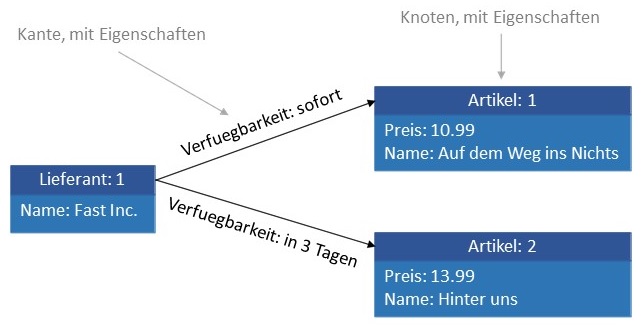
Mit einer Graphstruktur im Hintergrund kann eine Traversierung (sinngemäß: Durchquerung) des Datenbestands über die Beziehungen zwischen den Knoten deutlich schneller erfolgen, als in der Nachbildung einer Graphstruktur in relationalen Datenbanken.
Typische Vertreter