Das Einfügen von neuen Datensätzen in eine relationale Datenbank wird mit dem SQL-Statement INSERT
durchgeführt. Das allgemeine Schema eines INSERT-Statements ist in der folgenden Abbildung dargestellt
und wird in der folgenden Tabelle detailliert beschrieben
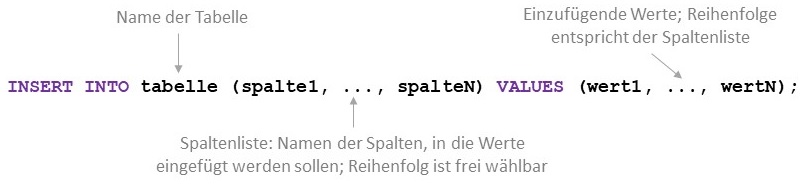
| Elemente von INSERT | Beschreibung |
tabelle |
Name der Tabelle, in die die Datensätze eingefügt werden sollen. In jedem INSERT-Statement kann genau eine Tabelle geändertwerden. |
Optional:(spalte1, ..., spalteN) |
Liste von Namen der Spalten, in die die Werte eingetragen werden sollen. Mindestens eine Spalte muss angegeben werden, die Reihenfolge der Spalten kann frei gewählt werden. Wird die Liste der Spalten weggelassen, müssen die Werte für alle Spalten der Tabelle eingefügt werden. |
(wert1, ..., wertN) |
Liste von Werten, die eingefügt werden sollen. Die Reihenfolge der Werte muss mit denen in der Spaltenliste übereinstimmen. Wurde keine Spaltenliste definiert, müssen die Werte für alle Spalten der Tabelle angegeben werden. Die Reihenfolge ist dann durch die Reihenfolge der Spalten in der Datenbanktabelle gegeben, die im CREATE TABLE-Statement angegeben wird. |
Folgende Beispiele veranschaulichen das INSERT-Statement anhand der folgenden Beispieltabelle
Gutscheinaktion, in der Daten zu Gutscheinaktionen eines Onlineshops gespeichert werden:
CREATE TABLE Gutscheinaktion (
AktionID INTEGER AUTO_INCREMENT,
Beginnaktion TIMESTAMP NOT NULL,
Endeaktion TIMESTAMP NOT NULL,
Titel VARCHAR(500) NOT NULL,
Beschreibung TEXT,
Gutscheincode VARCHAR(100) NOT NULL UNIQUE,
PRIMARY KEY (AktionID)
);
Ein Beispiel für das Einfügen eines neuen Datensatzes in die Tabelle Gutscheinaktion wird in der folgenden Abbildung
dargestellt.

Jeder INSERT-Befehl fügt einer Tabelle einen neuen Datensatz hinzu. Dabei wird eine neue Zeile
unten an die Tabelle angehangen. Obwohl im INSERT-Statement nicht alle Spalten zwingend angegeben
werden müssen, müssen in diese fehlenden Spalten jedoch auch Werte eingetragen werden. SQL sieht folgende Mechanismen vor, wie ein
DBMS mit fehlenden Werten umgehen kann:
NOT NULL definiert,
wird eine Fehlermeldung ausgegeben und die Ausführung von INSERT ohne Änderungen in der
DB abgebrochen.Wenn beim Einfügen von Werten in eine Tabelle ein übergebener Wert nicht den korrekten Datentyp der entsprechenden Spalte hat, dann wird der Datentyp nach Möglichkeit automatisch umgewandelt. Diese Umwandlung erfolgt verlustbehaftet, d.h. möglicherweise gehen Informationen beim Einfügen unbemerkt verloren. So werden beispielsweise Zeichenketten bei Überschreiten der Höchstlänge abgeschnitten und Zahlenwerte gerundet. Falls die Typumwandlung fehlerfrei durchgeführt werden kann, wird trotz Informationsverlust bei manchen DBMS eine Warnung oder Fehlermeldung zurückgegeben, bei anderen nicht. Falls ein Informationsverlust vermieden werden soll, muss die Typprüfung in der Geschäftsanwendung erfolgen, bevor die Werte dem DBMS übergeben werden.
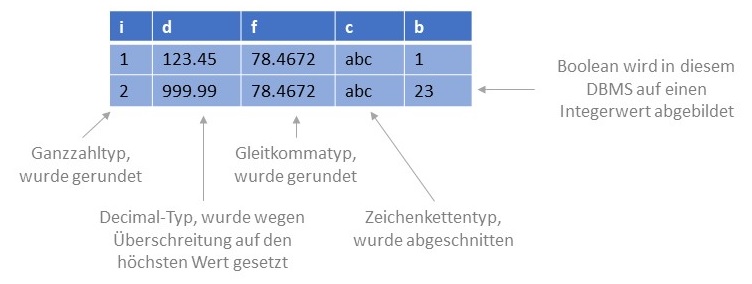
Folgendes Beispiel veranschaulicht die automatische Typumwandlung. Nach dem Anlegen der Tabelle t
CREATE TABLE t (
i INTEGER, d DECIMAL(5,2), f FLOAT, c VARCHAR(3), b BOOLEAN
);
und dem erfolgreichen Einfügen der zwei Datensätze
INSERT INTO t VALUES (1, 123.45, 78.46723, 'abc', TRUE);
INSERT INTO t VALUES (1.5, 12345.678, 78.46723456789, 'abcdefghij', 23);
sind in der Datenbank die in der folgenden Abbildung gezeigten Werte gespeichert.
Komplexe Datentypen wie DATE, TIME und TIMESTAMP werden seitens
vieler DBMS mit Umwandlungsfunktionen unterstützt. Die Werte dieser Datentypen können wie oben gezeigt entweder direkt oder
als Parameter der entsprechenden Umwandlungsfunktionen mit INSERT in die Datenbank eingefügt
werden. Wie diese Funktionen implementiert sind und wie sie sich im Fehlerfall verhalten, ist im Handbuch des DBMS beschrieben.
Häufig wird beim Fehlschlagen der Umwandlungsfunktionen ein NULL-Wert erzeugt, während beim Speichern ohne explizites Aufrufen
der Umwandlungsfunktionen ein Standarddefaultwert gespeichert wird.
Wird beispielsweise folgende Tabelle erstellt:
CREATE TABLE KTEST (
datumNull DATE, zeitNull TIME, zeitpunktNull TIMESTAMP,
datumNotNull DATE NOT NULL, zeitNotNull TIME NOT NULL,
zeitpunktNotNull TIMESTAMP NOT NULL
);
und werden anschließend die folgenden INSERT-Statements aufgerufen:
INSERT INTO KTEST VALUES ('2014-11-11', '12:12:12',
'2014-11-11 12:12:12', '2014-11-11', '12:12:12',
'2014-11-11 12:12:12');
INSERT INTO KTEST VALUES ('2014', '122X', '2014 122', '2014', '122', '2014 122');
liegt im DBMS (MySQL 5.6) folgender Datenbestand vor:
| datumNull | zeitNull | zeitpunktNull | datumNotNull | zeitNotNull | zeitpunktNotNull |
| 2014-11-11 | 12:12:12 | 2014-11-11 12:12:12 | 2014-11-11 | 12:12:12 | 2014-11-11 12:12:12 |
| 0000-00-00 | 00:01:22 | 0000-00-00 00:00:00 | 0000-00-00 | 00:01:22 | 0000-00-00 00:00:00 |
Werden die Daten des 2. INSERT-Statements jedoch explizit mit der folgenden Umwandlungsfunktion
eingefügt:
INSERT INTO KTEST VALUES (DATE('2014'), TIME('122X'), TIMESTAMP('2014 122'),
DATE('2014'), TIME('122'), TIMESTAMP('2014 122'));
so meldet das DBMS einen Fehler und trägt diesen Datensatz nicht ein. Denn beim Fehlschlagen der Umwandlung wird hier versucht NULL zu speichern, was aber bei NOT NULL-Attributen nicht möglich ist.
Mit SQL ist es möglich neue Datensätze durch Kopieren bestehender Datensätze zu erzeugen. Dabei wird das
INSERT-Statement mit dem SELECT-Statement kombiniert. Als
Voraussetzung dafür muss die Anzahl der Spalten und deren Datentypen der Ergebnistabelle des
SELECT-Statements mit der Tabelle übereinstimmen, in welche die Datensätze
eingefügt werden sollen. Das allgemeine Schema zum Kopieren von Datensätzen lautet:
INSERT INTO tabelle1 (spalte1, ..., spalteN)
SELECT spalte1, ..., spalteN FROM tabelle1 WHERE bedingung;
Folgendes Beispiel legt in der oben erzeugten Tabelle t neue Daten durch kopieren an:
INSERT INTO t SELECT * FROM t WHERE b = TRUE;
Häufig werden fachlich zusammenhängende Daten in mehrere einzelne Datensätze aufgeteilt und auf mehrere Tabellen verteilt. Insbesondere beim Einfügen solcher Datensätze ist zu gewährleisten, dass auch im Fehlerfall keine unvollständigen Daten in der Datenbank aufgenommen werden. Diese Anforderung unterstützen Datenbanken mit Transaktionen.