Die von industriellen Informationssystemen zu verarbeitenden Daten werden in der Regel in Datenbanken gespeichert, die innerhalb von Datenbanksystemen zur Verfügung gestellt werden. Datenbanken haben gegenüber einfachen Dateien eine Reihe von Vorteilen, die besonders für große Datenmengen relevant sind:
Neben den hier beschriebenen Standard-Datenbankmanagementsystemen (DBMS) haben in den letzten Jahren mit den sogenannten noSQL-Systemen auch eine Reihe von DBMS Verbreitung gefunden, die etwas andere Schwerpunkte setzen und beispielsweise für die Steigerung der Effizienz Abstriche bei der Konsistenz der Daten machen. Der Schwerpunkt der Beschreibung soll hier aber zuerst einmal auf den Standard-DBMS liegen.
Dabei unterscheidet man drei eng verwandte Begriffe, siehe Abbildung:
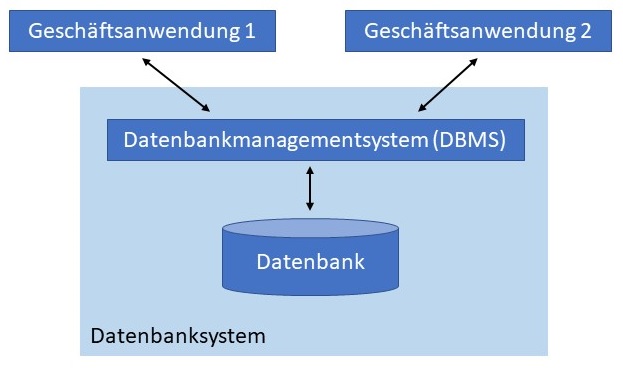
Benutzer arbeiten meist nur mit den Anwendungen, nicht dem DBMS oder der Datenbank.
Die am weitesten verbreitete Art und Weise, die Speicherung von Daten zu organisieren, ist das relationale Datenmodell. Datenbankmanagementsysteme zur Verwaltung von relational organisierten Datenbanken werden relationale Datenbankmanagementsysteme (RDBMS) genannt.
Damit die in einer Datenbank gespeicherte Information durch Informationssysteme verarbeitet werden kann, müssen die einzelnen Datensätze in einer vorgegebenen Struktur gespeichert werden. Zwar können die wichtigsten Daten zur Kundenverwaltung eines Onlineshops auch als Text zum Beispiel in einem Word-Dokument gespeichert werden:
"Herr Emil Schulze hat die Email-Adresse e.schulze@gmail.com und wird unter der Kundennummer 00200 geführt."
"Frau Silke Bauer mit der Kundennummer 00300 ist per Email unter der Adresse silke334@byom.de zu erreichen."
Allerdings kann das Lesen oder Ändern in dieser Form gespeicherter Kundendaten nicht automatisch oder durch IT-Systeme erfolgen. Daher
werden die zu speichernden Datensätze auf die wichtigsten Informationen reduziert und in eine für alle Datensätze einheitliche
Struktur gebracht. Die wichtigsten Eigenschaften der gerade beschriebenen Kunden sind Kundennummer, Anrede, Name, Vorname und Email-Adresse.
Eine Möglichkeit, die Kundendatensätze zu strukturieren, ist die Darstellung in einer Tabelle, deren Spalten jeweils eine
bestimmte Eigenschaft des Datensatzes speichern und deren Zeilen jeweils genau einen Datensatz enthalten.
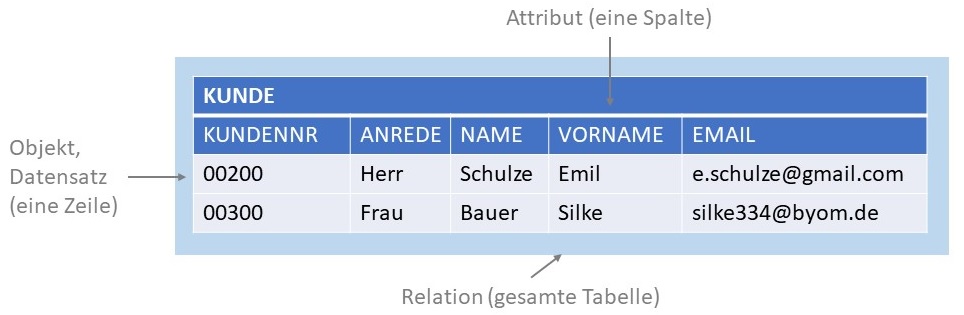
Alle in obiger Abbildung enthaltenen Datensätze haben die gleichen Attribute und damit auch die gleiche Struktur. Ein Datensatz wird auch Objekt genannt. Eine Menge von Objekten mit der gleichen Struktur - also denselben Attributen - wird in einer Relation gespeichert. Die in der Abbildung gezeigte Relation KUNDE hat die Struktur (KUNDENNR, ANREDE, NAME, VORNAME, EMAIL). Eine Relation wiederum wird in einer nach der Relation benannten Tabelle abgelegt.
Objekte in Relationen müssen jederzeit eindeutig identifiziert werden können, daher dürfen in einer Relation niemals zwei Datensätze die exakt gleichen Werte in allen Attributen haben. Die geforderte Eindeutigkeit ist aus fachlicher Sicht nicht immer möglich. Daher wird in einer Relation zusätzlich zu den fachlichen Attributen häufig auch ein technisches Attribut gespeichert, mit dem ein Datensatz eindeutig identifiziert werden kann. So ein Attribut heißt Identifizierer (engl.: identifier, ID-Attribut, kurz: ID). In relationalen Datenbanken werden die Identifizierer als Primärschlüssel (engl.: primary key) bezeichnet.
| Tipp |
| Fachliche IDs und technische IDs immer trennen. Niemals fachliche IDs als technische IDs oder technische IDs als fachliche IDs einsetzen! Zwar gibt es auch fachliche Identifizierer, im Beispiel oben die Kundennummer. Dennoch sollte eine Datenbankstruktur die technische Identifizierbarkeit der Datensätze immer durch eine eigene ID sicherstellen. |
Die folgende Tabelle enthält die oben bereits eingeführte Relation KUNDE, die um das Attribut KUNDEID erweitert wurde. Dieses Attribut dient in dieser Relation als Primärschlüssel.
| Kundendaten eines Onlineshops | |||||
|---|---|---|---|---|---|
| KUNDE | |||||
| KUNDEID | KUNDENNR | ANREDE | NAME | VORNAME | |
| 094904 | 00100 | Herr | Schwarz | David | david.schwarz@hkf-online.de |
| 098483 | 00200 | Herr | Schulze | Emil | e.schulze@gmail.com |
| 112536 | 00300 | Frau | Bauer | Silke | silke334@byom.de |
| 234938 | 00400 | Frau | Meier | Frauke | lieschen234@yahoo.com |
| 293933 | 00500 | Herr | Ernst | Reiner | ernst-reiner@tkom.org |
| 338457 | 00600 | Frau | Weber | Maria | weberchen@trash-mail.com |
In nahezu allen praktischen Anwendungsfällen reicht eine einzelne Relation (Tabelle) nicht aus, um alle benötigten Informationen zu einem fachlichen Objekt zu speichern. So müssen für den Betrieb eines Onlineshops neben den wichtigsten Kundendaten zu jedem Kunden auch dessen Meldeadresse sowie verschiedene Liefer- und Rechnungsadressen geseichert werden können. Dazu soll in diesem Fall eine Relation ANSCHRIFT mit den Attributen (ADRESSEID, STRASSE, HAUSNUMMER, PLZ, ORT, LAND) verwendet werden, die in der folgenden Tabelle dargestellt ist.
| Tabelle mit Relation ADRESSE | |||||
|---|---|---|---|---|---|
| ADRESSE | |||||
| ADRESSEID | STRASSE | HAUSNUMMER | PLZ | ORT | LAND |
| 2 | Berliner Str. | 55b | 60311 | Frankfurt | Deutschland |
| 3 | Marienstr. | 25 | 10117 | Berlin | Deutschland |
Mit den beiden Relationen KUNDE und ADRESSE ist es nun möglich Kundendaten und Adressdaten strukturiert zu speichern. Allerdings fehlt noch die Zuordnung von Objekten der Relation KUNDE zu Objekten der Relation ADRESSE. Diese Zuordnung erfolgt über sogenannte Beziehungen. Jede Beziehung hat einen eindeutigen Namen. Es können die folgenden Typen von Beziehungen anhand ihrer Kardinalität (auch: Stelligkeit, Multiplizität) unterschieden werden: 1:1-Beziehung, 1:N-Beziehung sowie N:M-Beziehung.
Nachfolgende Abbildung veranschaulicht exemplarisch die 1:1-Beziehung "Hauptwohnsitz". Diese Beziehung verbindet einen Datensatz der
Relation KUNDE mit genau einem Datensatz der Relation ADRESSE.

Die folgende Abbildung zeigt eine um das Attribut ADRESSEID erweiterte Relation KUNDE. Mit dem im Attribut ADRESSEID gespeicherten Wert
muss sich ein Datensatz ADRESSE eindeutig identifizieren lassen. Daher wird im Datenmodell gefordert, dass als Wert von ADRESSEID nur ein
bereits existierender Identifizierer (Primärschlüssel) der Relation ADRESSE gespeichert wird. Der Identifizierer von ADRESSE ist
das Attribut ADRESSEID. Daher müssen die konkreten Werte von ADRESSEID in den Objekten vom Typ KUNDE ein Wert aus der Spalte ADRESSEID
der Relation ADRESSE sein. Der Primärschlüssel von ADRESSE wird damit auch in der "fremden" Relation KUNDE verwendet. Diese Art
der Verwendung von Primärschlüsseln einer anderen Tabelle wird Fremdschlüssel genannt. Ein Fremdschlüssel referenziert
den Primärschlüssel einer anderen Tabelle, die mit der aktuellen Tabelle in Beziehung steht.

In nachstehender Abbildung ist die 1:N-Beziehung "Lieferadresse" dargestellt, mit der genau ein Objekt der Relation KUNDE mit mehreren
Objekten der Relation ADRESSE verbunden wird.

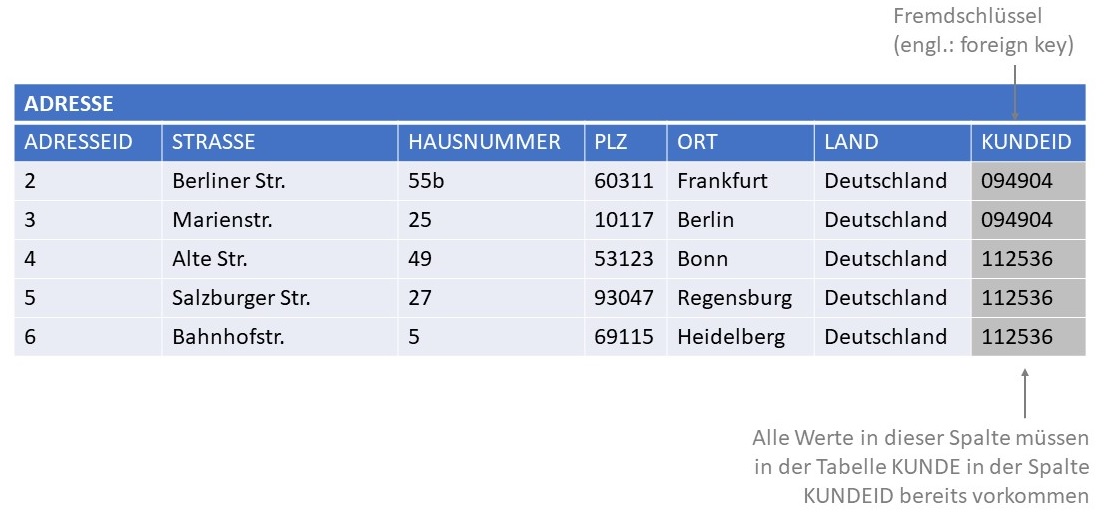
Die folgende Abbildung stellt die erweiterte Relation ADRESSE dar, die um ein Attribut KUNDEID ergänzt wurde. In diesem Attribut
werden Werte der Spalte KUNDEID der Tabelle KUNDE gespeichert. Das Attribut KUNDEID ist der Primärschlüssel der Relation KUNDE.
Damit können über dieses Attribut in der Tabelle ADRESSE eindeutig die tatsächlichen Kunden zu den Datensätzen aus
ADRESSE identifiziert werden.
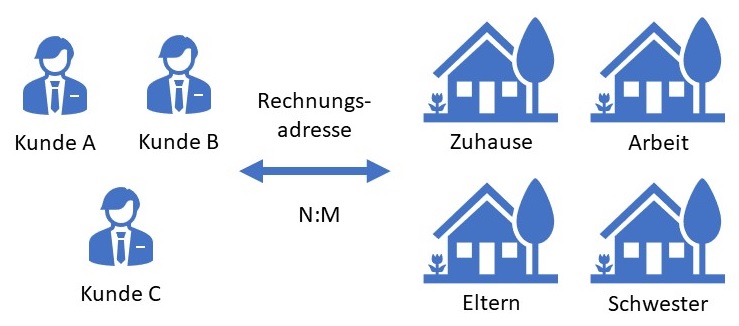
Nachfolgende Abbildung veranschaulicht die N:M-Beziehung "Rechnungsadresse". Diese Beziehung stellt eine Verbindung von M Objekten der
Relation KUNDE mit N Objekten der Relation ADRESSE her.
Um N:M-Beziehungen im relationalen Datenmodell abzubilden, werden sogenannte Beziehungstabellen benötigt. Die folgende Abbildung zeigt
exemplarisch eine Beziehungstabelle um die N:M-Beziehung zwischen Datensätzen der Relation KUNDE und Datensätzen der Relation
ADRESSE zu speichern. Eine Beziehungstabelle hat als Attribute die Identifizierer der Relationen, die sie in Beziehung setzen soll. Im
konkreten Beispiel also ADRESSEID der Relation ADRESSE sowie KUNDEID der Relation KUNDE. Datensätze dieser Beziehungstabelle bestehen
nur aus Fremdschlüsseln.
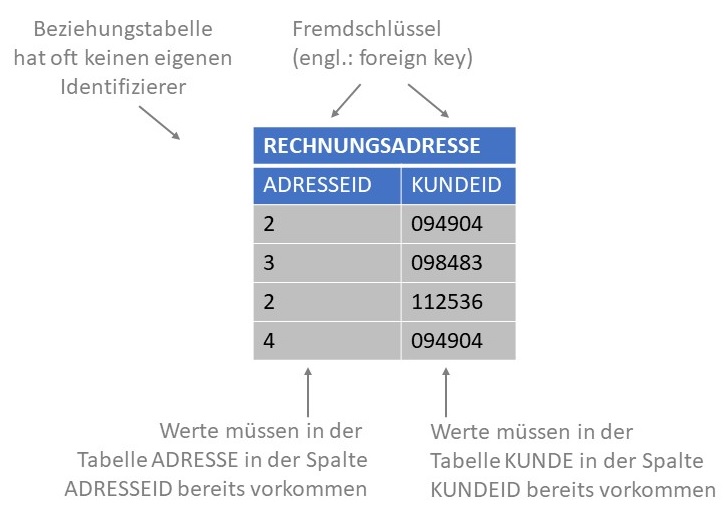
Der Primärschlüssel der Tabelle RECHNUNGSADRESSE ergibt sich aus der Kombination von ADRESSEID und KUNDEID. Damit handelt es sich um einen zusammengesetzten Primärschlüssel.
Ganz allgemein erfolgt das Eintragen von Datensätzen in relationale Datenbanken nach folgendem Schema:
Beispiel
Folgender Sachverhalt soll in dem oben bereits vorgestellten relationalen Datenschema gespeichert werden:
"Frau Lisa Wagner mit der Email-Adresse lisa-wagner@posteo.de soll unter der Kundennummer 00700 gespeichert werden. Sie wohnt in Hamburg (20095) in der Domstr. 18. Sie hat bis jetzt fast alle Sendungen und Rechnungen zu sich nach Hause geschickt bekommen. Die letzte Bestellung inkl. Rechnung wurde allerdings nach 01189 Dresden (Deutschland), in die Stuttgarter Str. 73 versendet."
Zum Eintragen dieser Daten müssen drei Tabellen geändert werden: KUNDE, ADRESSE und RECHNUNGSADRESSE. Diese Tabellen sind unten dargestellt. Dort werden jeweils an das Ende der Tabelle die neuen Objekte hinzugefügt: ein Objekt in der Relation KUNDE, zwei Objekte in der Relation ADRESSE sowie zwei Objekte in der Relation RECHNUNGSADRESSE. Die in dem Beispiel eingefügten Werte sind fett markiert. Dabei sind neben der Eindeutigkeit aller Primärschlüssel auch folgende Fremdschlüsselbeziehungen zu beachten:
| KUNDE | ||||||
|---|---|---|---|---|---|---|
| KUNDEID | KUNDENNR | ANREDE | NAME | VORNAME | ADRESSEID | |
| 094904 | 00100 | Herr | Schwarz | David | david.schwarz@hkf-online.de | 2 |
| 112536 | 00300 | Frau | Bauer | Silke | silke334@byom.de | 3 |
| 348902 | 00700 | Frau | Wagner | Lisa | lisa-wagner@posteo.de | 7 |
| ADRESSE | ||||||
|---|---|---|---|---|---|---|
| ADRESSEID | STRASSE | HAUSNUMMER | PLZ | ORT | LAND | KUNDEID |
| 2 | Berliner Str. | 55b | 60311 | Frankfurt | Deutschland | 094904 |
| 3 | Marienstr. | 25 | 10117 | Berlin | Deutschland | 094904 |
| 4 | Alte Str. | 49 | 53123 | Bonn | Deutschland | 112536 |
| 5 | Salzburger Straße | 27 | 93047 | Regensburg | Deutschland | 112536 |
| 6 | Bahnhofstr. | 5 | 69115 | Heidelberg | Deutschland | 112536 |
| 7 | Domstr. | 18 | 20095 | Hamburg | Deutschland | 348902 |
| 8 | Stuttgarter Straße | 73 | 01189 | Dresden | Deutschland | 348902 |
| RECHNUNGSADRESSE | |
|---|---|
| ADRESSEID | KUNDEID |
| 2 | 094904 |
| 2 | 112536 |
| 4 | 094904 |
| 7 | 348902 |
| 8 | 348902 |