Zu Beginn des Datenbankentwurfs werden alle relevanten Entitäten sowie deren Beziehungen und Attribute identifiziert und dokumentiert.
Als Ergebnis dieser Aktivitäten entsteht ein fachliches Datenmodell. Häufig wird das fachliche Datenmodell in den Aktivitäten
des Requirements Engineerings begonnen. Als Ergebnis der Spezifikation liegt anschließend im Idealfall ein detailliertes fachlich-technisches
Datenmodell vor. Dieses Datenmodell wird im Datenbankumfeld als konzeptionelles Datenmodell bezeichnet. Ein konzeptionelles Datenmodell
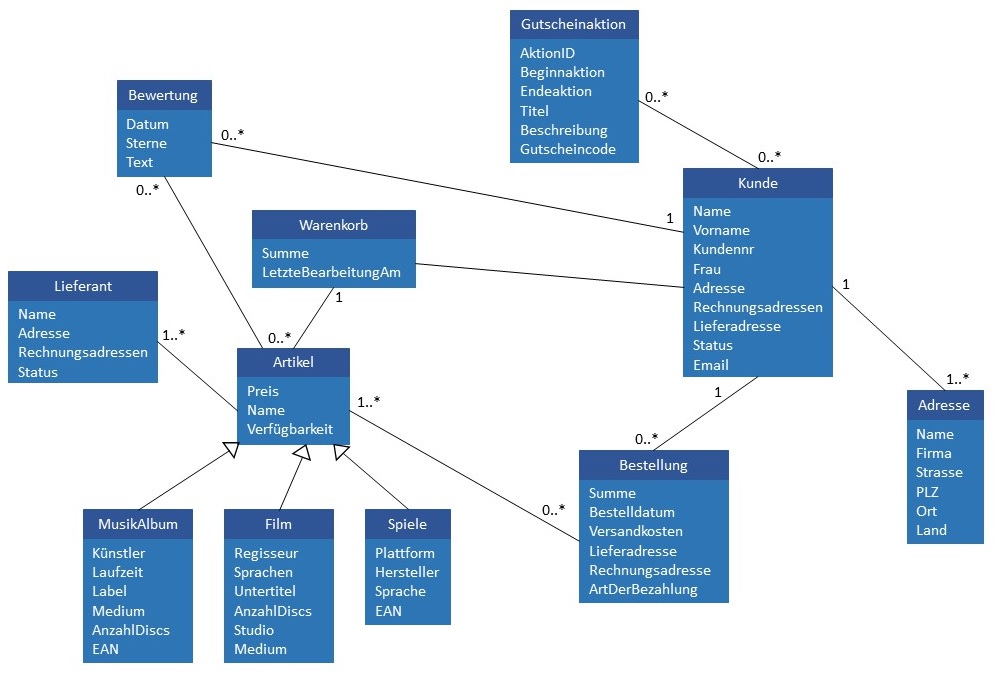
enthält noch keine datenbankspezifischen Informationen. Die folgende Abbildung zeigt exemplarisch ein konzeptionelles Datenmodell, das
einen Auszug eines Modells für einen Onlineshop enthält. Ein konzeptionelles Modell ist in der Regel ein Netzwerk aus Entitäten
(auch: Klassen) und enthält, wie im Beispiel dargestellt, auch Vererbungsbeziehungen.
Als physikalisches Datenmodell wird ein Datenmodell bezeichnet, das alle Einschränkungen und Eigenschaften relationaler Datenbanken berücksichtigt. So können in einer relationalen Datenbank nur 1:C-Beziehungen sowie 1:CN-Beziehungen direkt abgebildet werden. Auf Basis eines physikalischen Datenmodells kann anschließend die konkrete Tabellenstruktur einer relationalen Datenbank erstellt werden. Außerdem wird in einem physikalischen Datenmodell die tatsächliche Struktur einer Datenbank dokumentiert. Ein solches Modell enthält Tabellen, Attribute und Primärschlüssel sowie über Fremdschlüssel modellierte Beziehungen. Darüber hinaus sollten alle Bezeichner im physikalischen Datenmodell keine Sonderzeichen wie Umlaute beinhalten.
Trotz der Einschränkungen in relationalen Datenbanken ist es möglich, die Struktur des konzeptionellen Datenmodells in Tabellen eines DBMS abzubilden. Dazu werden alle Beziehungen aus dem konzeptionellen Datenmodell, die nicht direkt in eine Datenbank abbildbar sind, vorher in das physikalische Datenmodell transformiert. Dabei werden 1:1-Beziehungen sowie 1:N-Beziehungen mit Hilfe von 1:C- bzw. 1:CN-Beziehungen und zusätzlichen Bedingungen abgebildet. N:M-Beziehungen und Vererbungsbeziehungen müssen zuerst auf 1:N-Beziehungen abgebildet werden, bevor das konkrete Datenbankschema erstellt werden kann.
Eine Auswahl möglicher Abbildungen von 1:1-Beziehungen in das physikalische Datenmodell wird in der folgenden Tabelle dargestellt.
| Abbildung von 1:1-Beziehungen | |||
|---|---|---|---|
| Konzeptionelles Datenmodell |
Physikalisches Datenmodell |
Beschreibung | |
| 1:1 | 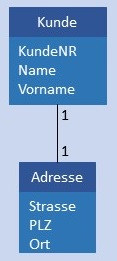 |
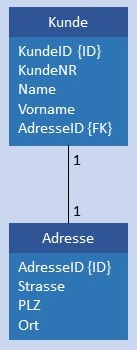 |
Kunde und Adresse werden in je einer Tabelle gespeichert, in Kunde ist im Attribut AdresseID der Primärschlüssel von Adresse gespeichert. Bedingung: Jeder Wert Adresse.AdresseID muss in Kunde.AdresseID genau 1 x vorkommen.  |
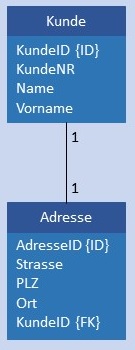 |
ODER Kunde und Adresse werden in je einer Tabelle gespeichert, in Adresse ist im Attribut KundeID der Primärschlüssel von Kunde gespeichert. Bedingung: Jeder Wert Kunde.KundeID muss in Adresse.KundeID genau 1 x vorkommen.  |
||
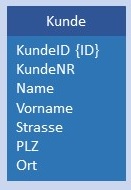 |
ODER Zusammenfassung in einer Tabelle. Ist nur möglich, falls die Tabelle Adresse keine weiteren Beziehungen zu anderen Tabellen hat. Bedingung: Die Kombination der Adress-Attribute Strasse, PLZ und Ort muss eindeutig sein. |
||
Die Abbildungen von 1:C- sowie von C:C-Bedingungen in das physikalische Datenmodell werden in der folgenden Tabelle dargestellt.
| Abbildung von C:C-Beziehungen | |||
|---|---|---|---|
| Konzeptionelles Datenmodell |
Physikalisches Datenmodell |
Beschreibung | |
| 1:C | 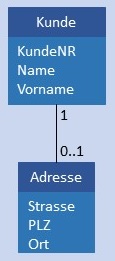 |
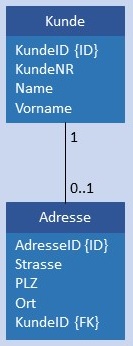 |
Kunde und Adresse werden in je einer Tabelle gespeichert, in Adresse ist im Attribut KundeID der Primärschlüssel von Kunde gespeichert. Bedingung: Jeder Wert KundeID in Adresse darf nicht NULL sein und höchstens 1 x vorkommen. |
| C:C | 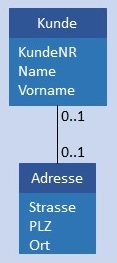 |
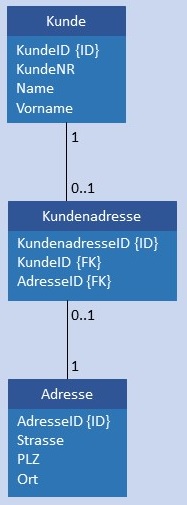 |
Kunde und Adresse werden in je einer Tabelle gespeichert. Zusätzlich gibt es noch eine Tabelle Kundenadresse mit den beiden Fremdschlüsseln AdresseID und KundeID als Attribute. Die Tabelle Kundenadresse wurde hier exemplarisch mit dem künstlichen Schlüssel KundenadresseID versehen. Bedingung: In Kundenadresse sind die Werte AdresseID und KundeID nicht NULL und in beiden Spalten ist jeder Wert höchstens 1 x enthalten.  |
Die Abbildungen von Beziehungen der Form 1:N in das physikalische Datenmodell werden in der folgenden Tabelle dargestellt.
| Abbildung von 1:N-Beziehungen | |||
|---|---|---|---|
| Konzeptionelles Datenmodell |
Physikalisches Datenmodell |
Beschreibung | |
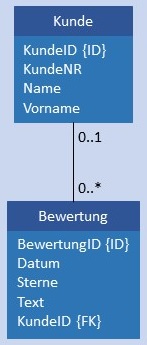
| 1:N | 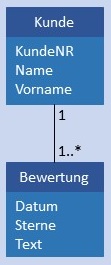 |
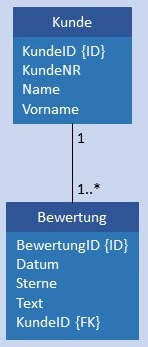 |
Kunde und Bewertung werden in je einer Tabelle gespeichert, in Bewertung ist im Attribut KundeID als Fremdschlüssel der Primärschlüssel von Kunde gespeichert. Bedingung: Das Attribut KundeID in Bewertung darf nicht NULL sein und muss jeden Wert von KundeID in Kunde mindestens 1 x enthalten.  |
| 1:CN | 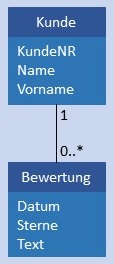 |
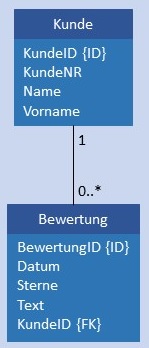 |
Kunde und Bewertung werden in je einer Tabelle gespeichert, in Bewertung ist im Attribut KundeID als Fremdschlüssel der Primärschlüssel von Kunde gespeichert. Bedingung: Das Attribut KundeID in Bewertung darf nicht NULL sein. |
| C:CN | 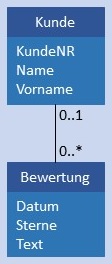 |
 |
Kunde und Bewertung werden in je einer Tabelle gespeichert, in Bewertung ist im Attribut KundeID als Fremdschlüssel der Primärschlüssel von Kunde gespeichert. In diesem Fall darf das Attribut KundeID in Bewertung NULL sein. |
| C:N | 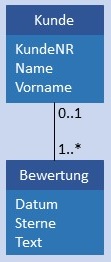 |
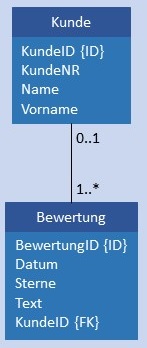 |
Kunde und Bewertung werden in je einer Tabelle gespeichert, in Bewertung ist im Attribut KundeID als Fremdschlüssel der Primärschlüssel von Kunde gespeichert. Auch in diesem Fall darf das Attribut KundeID in Bewertung NULL sein. Bedingung: Dabei muss jeder Wert von KundeID in Kunde mindestens 1 x als Wert in KundeID von Bewertung vorhanden sein. |
Die Abbildungen von Beziehungen der Form N:M in das physikalische Datenmodell werden in der folgenden Tabelle dargestellt.
| Abbildung von N:M-Beziehungen | |||
|---|---|---|---|
| Konzeptionelles Datenmodell |
Physikalisches Datenmodell |
Beschreibung | |
| N:M | 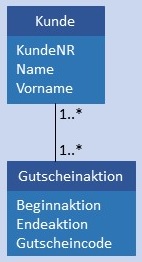 |
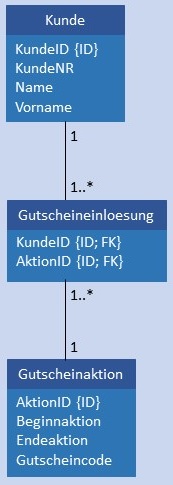 |
Kunde und Gutscheinaktion werden in je einer Tabelle gespeichert. Zusätzlich gibt es noch eine Tabelle Gutscheineinloesung mit den beiden Fremdschlüsseln KundeID und AktionID als Attribute. Da sowohl die Werte in KundeID als auch in AktionID jeweils mehrfach vorkommen können, kann ein aus beiden Werten zusammengesetzter Primärschlüssel eingesetzt werden. Möglich ist auch der Einsatz eines künstlichen Schlüssels für Gutscheineinloesung. Bedingung: Jeder Wert von KundeID in Kunde muss mindestens 1 x als Wert von KundeID in Gutscheineinloesung vorhanden sein. Jeder Wert von AktionID in Gutscheinaktion muss in AktionID von Gutscheineinloesung mindestens 1 x enthalten sein.  |
| N:CM | 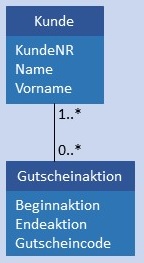 |
 |
Die Umsetzung in Tabellen einer Datenbank erfolgt wie bei der N:M-Beziehung. Bedingung: Jeder Wert von AktionID in Gutscheinaktion muss in AktionID von Gutscheineinloesung mindestens 1 x enthalten sein. |
| CN:CM | 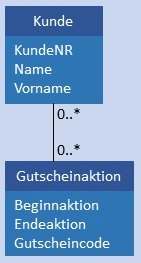 |
 |
Die Umsetzung in Tabellen einer Datenbank erfolgt wie bei der N:M-Beziehung. Bedingung: Dabei werden jedoch keine Anforderungen auf das einmalige Verwenden von KundeID oder AktionID in Gutscheineinloesung gestellt. |
Die Abbildungen von rekursiven Beziehungen in das physikalische Datenmodell werden in der folgenden Tabelle dargestellt.
| Abbildung von rekursiven Beziehungen | ||
|---|---|---|
| Konzeptionelles Datenmodell |
Physikalisches Datenmodell |
Beschreibung |
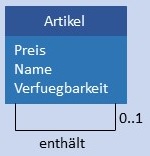 |
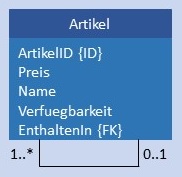 |
Artikel werden in einer Tabelle gespeichert. Die Rekursion wird modelliert über einen Fremdschlüssel, der zurück auf die Tabelle Artikel zeigt. 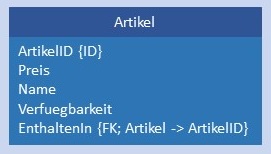 |
Relationale Datenbanken unterstützen keine Vererbungsbeziehungen. Daher müssen auch diese Art von Beziehungen auf Tabellen
und deren Beziehungen abgebildet werden. Verschiedene Strategien für die erforderlichen Abbildungen werden im Folgenden anhand des in
untenstehender Abbildung gezeigten einfachen Beispiels vorgestellt.
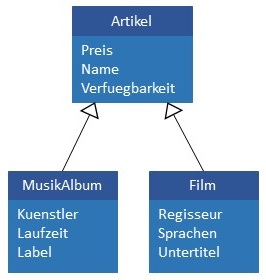
In der Praxis sind die folgenden Abbildungsstrategien für Vererbung weit verbreitet:
Single Table
Die Abbildungsstrategie Single Table (auch: Single Table per Class Hierarchy Strategy) bildet wie in der folgenden
Abbildung eine gesamte Klassenhierarchie auf eine Tabelle ab. Alle Objekte zu allen Klassen in der Vererbungshierarchie werden in genau
einer Tabelle gespeichert.
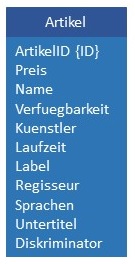
Mit einem optionalen Attribut "Diskriminator" kann zu jedem Datensatz explizit der Typ (der Name der Klasse) gespeichert werden. Die Vor- und Nachteile von Single Table werden in der folgenden Tabelle gegenüber gesellt.
| Vor- und Nachteile der Single-Table-Strategie | |
|---|---|
| Vorteile | Nachteile |
| Sehr schnell lesender und schreibender Zugriff auf Daten, da nur eine Tabelle gelesen werden muss. |
Je komplexer die Vererbungshierarchie ist, desto größer wird eine einzelne Tabelle. Das führt bei großen Datenmengen ggf. zu deutlichen Performanceverlusten. |
| Für das Lesen und Schreiben auf der Datenbank reicht jeweils genau ein SQL-Statement aus. |
In komplexen Vererbungshierarchien wird die Tabelle sehr viele NULL-Elemente enthalten. Der reservierte Speicherplatz wird damit nicht effizient genutzt. |
| Effizienter Zugriff auf Beziehungen zwischen Klassen der Vererbungshierarchie. |
|
Joined Subclass Table
In der Joined-Subclass-Table-Strategie wird jede Klasse der Vererbungshierarchie, wie in der folgenden
Abbildung dargestellt, in einer eigenen Tabelle gespeichert. Das gilt auch für abstrakte Klassen, also Klassen, die selbst keine
Instanzen haben dürfen, sondern nur deren Unterklassen. Jede Unterklasse enthält einen Fremdschlüssel zu den
Datensätzen der Attribute ihrer Oberklasse. Um alle Attribute einer Klasse aus der Datenbank zu lesen bzw. zu schreiben, müssen
daher die Daten aus allen Tabellen aller Oberklassen ebenfalls ausgelesen bzw. geschrieben werden.
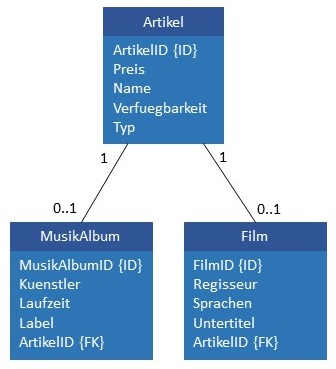
Die Vor- und Nachteile der Joined-Subclass-Table-Strategie werden in der folgenden Tabelle gegenüber gesellt.
| Vor- und Nachteile der Joined-Subclass-Table-Strategie | |
|---|---|
| Vorteile | Nachteile |
| Strategie mit der geringsten Redundanz in den gespeicherten Daten. | Verglichen mit den anderen Strategien die langsamste Abbildung von Vererbung. |
| Einfaches Hinzufügen von weiteren Unterklassen sehr leicht möglich. Bereits bestehende Tabellen müssen dabei nicht in ihrer Struktur verändert werden. |
Um Daten zu lesen und zu schreiben, müssen immer mehrere Tabellen angefragt werden. Daher bestehen die Anfragen aus mehreren SQL-Statements. |
| Die Daten aus Oberklassen können mit einfachen Datenbankmitteln (Fremdschlüssel und Join) geladen werden. |
Ausnahme: Zugriffe auf die oberste Oberklasse erfolgen sehr schnell. |
Table per Class
Mit der Strategie Table per Class wird ebenfalls für jede Klasse der Vererbungshierarchie, wie in der
folgenden Abbildung gezeigt, eine eigene Tabelle erstellt. Dies gilt allerdings nur für konkrete, also nicht abstrakte, Klassen.
Die eigene Tabelle pro Klasse enthält jedoch im Unterschied zur Strategie Joined Subclass Table alle Attribute, die zu konkreten
Objekten dieser Klasse gespeichert werden. Um einen Datensatz einer bestimmten Klasse zu laden, reicht ein Zugriff auf die
korrespondierende Tabelle aus.

Die Vor- und Nachteile der Table-per-Class-Strategie werden in der folgenden Tabelle gegenüber gesellt.
| Vor- und Nachteile der Table-per-Class-Strategie | |
|---|---|
| Vorteile | Nachteile |
| Falls der Klassenname bekannt ist, sind sehr effiziente Zugriffe auf die Datenbank möglich, da alle benötigten Informationen in einer Tabelle gespeichert sind. |
Beziehungen zu Objekten in einer Oberklasse, bei denen nicht eindeutig erkennbar ist, in welcher Unterklasse sich das einzelne Objekt befindet, sind sehr schwierig und aufwendig umzusetzen. |
| Einfaches Hinzufügen von weiteren Klassen ist sehr leicht möglich. Bereits bestehende Tabellen müssen dabei nicht in ihrer Struktur verändert werden. |
Falls die konkrete Unterklasse nicht bekannt ist, kann auch die Tabelle nicht gefunden werde, in der der betreffende Datensatz gespeichert ist. |
| Auswertungen über die gesamte Oberklasse benötigen eine Vielzahl von SQL-Befehlen, da die Objekte der Oberklasse über verschiedene Unterklassen verteilt sind. |
|